{kind=link}

A memory-enhanced GraphRAG framework that connects unstructured passages, extracted facts, and abstract schemas in a three-layer memory for reliable retrieval and generation.
- [2026-05-17] Our MemGraphRAG for memory-enhanced RAG is accepted by KDD'26.
- [2026-04-07] Our ProbeRAG for RAG faithfulness is accepted by ACL'26.
- [2026-04-07] Our BAPO for reliable agentic search is accepted by ACL'26.
- [2026-04-07] Our LegalGraphRAG for reliable legal reasoning is accepted by ACL'26.
- [2026-04-07] Our LogicPoison, a GraphRAG attack model, is accepted by ACL'26.
- [2026-01-26] Our LinearRAG for efficient GraphRAG is accepted by ICLR’26.
- [2026-01-26] Our GraphRAG Benchmark is accepted by ICLR’26.
- [2025-11-08] Our LogicRAG is accepted by AAAI'26.
- [2025-10-27] We release LinearRAG, a relation-free graph construction method for efficient GraphRAG.
- [2025-06-06] We release the GraphRAG Benchmark for evaluating GraphRAG models.
- [2025-05-14] We release the GraphRAG Benchmark dataset.
- [2025-01-21] We release the GraphRAG survey.
📃 Please cite our paper if you find this repository helpful.
📫 Contact: {xiangzhishang,wuchuanjie}@stu.xmu.edu.cn, qinggangzhang@jlu.edu.cn
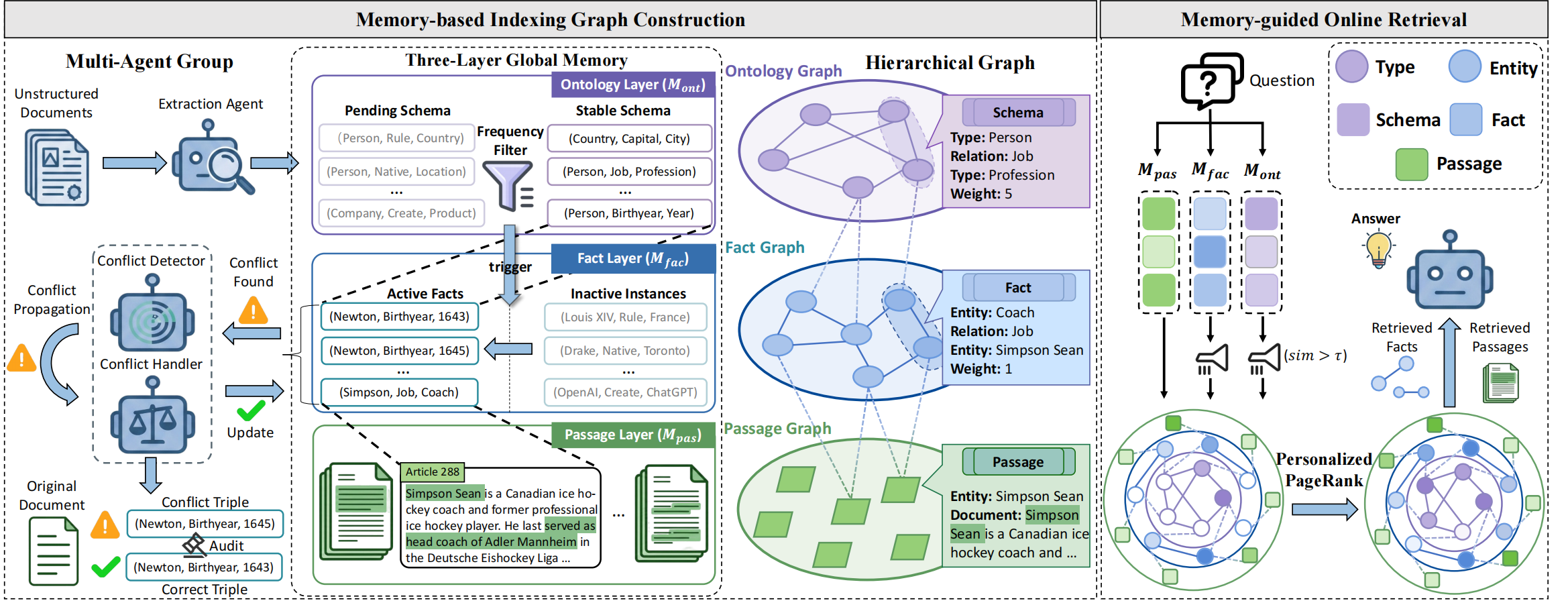
MemGraphRAG organizes knowledge into three connected layers:
- Schema layer: abstract ontology triples such as
(head type, relation, tail type). - Fact layer: concrete relation triples extracted from the corpus.
- Passage layer: original text chunks that support the facts.
- Three-layer memory: bidirectional links among schemas, facts, and source passages.
- Ontology induction: abstracts facts into reusable schemas and filters low-frequency patterns.
- Conflict-aware construction: detects hard conflicts with passage evidence and resolves connected conflict groups.
- Memory-derived graph: creates type, entity, and passage nodes after conflict resolution.
- Graph-enhanced retrieval: combines embedding similarity and Personalized PageRank.
- Batch QA: records answers, retrieved documents, scores, latency, and token usage.
Python 3.10 or later is recommended. The online pipeline uses an OpenAI-compatible LLM endpoint and a local Hugging Face embedding model.
conda create -n memgraphrag python=3.10
conda activate memgraphrag
git clone https://github.com/XMUDeepLIT/MemGraphRAG.git
cd MemGraphRAG
pip install -r requirements.txtFor offline OpenIE, also install vllm or llama-factory. Optional embedding backends may require packages such as gritlm.
export OPENAI_API_KEY="your-api-key"
export CUDA_VISIBLE_DEVICES="0"
LLM_NAME="gpt-4o-mini"
LLM_BASE_URL="https://your-openai-compatible-endpoint/v1"
EMBEDDING_MODEL="/path/to/bge-large-en-v1.5"Use the same LLM_NAME and EMBEDDING_MODEL for indexing and retrieval because their values identify the saved graph and embedding stores.
Run from the repository root. The corpus must be a UTF-8 plain-text file.
python code/index.py \
--corpus datasets/corpus/corpus.txt \
--save-dir outputs/corpus \
--llm-name "$LLM_NAME" \
--llm-base-url "$LLM_BASE_URL" \
--embedding-model "$EMBEDDING_MODEL" \
--tokenizer "$EMBEDDING_MODEL" \
--chunk-size 256 \
--chunk-overlap 32 \
--artifact-mode defaultAdd --force-index-from-scratch and --force-openie-from-scratch to rebuild the corresponding caches.
outputs/corpus/
├── openie_results_ner_<llm>.json
├── initial_memory_with_schema.json
├── memory.json
├── graph_from_memory/
│ ├── memory_graph.json
│ └── memory_graph.graphml
└── <llm>_<embedding_model>/
├── graph.graphml
├── chunk_embeddings/
├── entity_embeddings/
└── fact_embeddings/
python code/retrieval_dataset_test.py \
--questions datasets/corpus/small-questions.json \
--save-dir outputs/corpus \
--output results/corpus/qa_results.json \
--llm-name "$LLM_NAME" \
--llm-base-url "$LLM_BASE_URL" \
--embedding-model "$EMBEDDING_MODEL" \
--question-type all \
--sample-num 0 \
--skip-fact-rerank true \
--fact-similarity-threshold 0.4 \
--use-raw-threshold-filter trueThe result JSON contains the run summary, effective configuration, solutions, raw responses, metadata, retrieved passages.
code/run_index.sh and code/run_retrieval_test.sh are editable launch templates. Adjust their interpreter, paths, endpoint, model, and GPU settings before use.
The QA runner accepts a flat list of question objects or questions grouped by type:
[
{
"source": "dataset-name",
"questions": {
"type1": [
{
"id": "type1_0",
"question": "Your question",
"answer": "Gold answer",
"evidence": ["Optional supporting evidence"]
}
]
}
}
]Set --question-type type1 for one group or --question-type all for all groups. --sample-num 0 loads every question.
📦 .
├── 📂 code
│ ├── 📂 src
│ │ ├── 📂 embedding_model # Embedding backends
│ │ ├── 📂 evaluation # Retrieval and QA metrics
│ │ ├── 📂 information_extraction # Online and offline OpenIE
│ │ ├── 📂 llm # OpenAI-compatible and vLLM backends
│ │ ├── 📂 prompts # Extraction, linking, QA, memory prompts
│ │ ├── 📂 utils # Configuration and utilities
│ │ ├── MemGraphRAG.py # Pipeline orchestration
│ │ ├── Memory.py # Three-layer memory
│ │ ├── embedding_store.py # Persistent embedding stores
│ │ └── rerank.py # Fact reranking and filtering
│ ├── index.py # Indexing CLI
│ ├── retrieval_dataset_test.py # Retrieval and QA CLI
│ ├── run_index.sh # Indexing template
│ └── run_retrieval_test.sh # Retrieval template
├── 📂 datasets # Example corpora and QA datasets
├── 📂 outputs # Generated artifacts
└── 📜 README.md
Our framework builds upon the excellent work HippoRAG. We also thank the open-source communities behind Hugging Face Transformers, OpenAI-compatible APIs, and igraph.
@article{wu2026memgraphrag,
title={MemGraphRAG: Memory-based Multi-Agent System for Graph Retrieval-Augmented Generation},
author={Wu, Chuanjie and Xiang, Zhishang and Tang, Yunbo and Chen, Zerui and Zhang, Qinggang and Su, Jinsong},
journal={arXiv preprint arXiv:2606.00610},
year={2026}
}Links: arXiv
This project is released under the MIT License.