

The agent-to-agent codebase wiki — a token-efficient codebase map for AI agents. Zero dependencies, autonomous, built for LLM context windows.
Wikifier gives AI coding agents and LLMs a living, queryable map of any codebase — file health matrix, dependency graphs, per-file summaries — so they can look things up instead of re-reading full source files into their context window. From small scripts to 50,000-file monorepos, agents get fast code navigation, import analysis, and circular dependency detection without burning tokens on code they don't need right now.
It is an automated library for AI agents: an agent asks for the map, gets a compact answer, and keeps the wiki current itself as it works.
Every AI coding assistant faces the same problem: context windows are finite and raw source code is expensive. Re-reading a 2,000-line file to answer "what does this module do and who imports it?" wastes tokens that could go toward actual reasoning.
Wikifier solves this with a small set of generated, queryable artifacts:
file_health.md— a documentation health matrix (🟢 current / 🟡 stale / 🔴 broken) so agents know what to trust and what to fix firstlibrary.md— the codebase map: a Mermaid dependency diagram, resolved import tables, circular dependency report with break recommendations, and a confidence-scored risk snapshot- Per-file
*.wiki.mdnotes — short "what this file is for" summaries, maintained by the agents themselves journal/— a semantic audit trail of why every change was made, written byrecord-change
The result: an LLM looks up a 50-token summary instead of ingesting a 5,000-token file. That's the entire point — token-efficient code understanding for AI agents.
Agents keep the wiki alive through a strict but lightweight workflow (the full LLM-ready protocol lives in skills/run.md):
wikifier check-changes # what changed? (incremental, sub-second)
# read file_health.md + pending_updates.md, prioritize 🔴 then 🟡
# ... edit source ...
wikifier record-change "path/file.py" "why this changed" # mandatory — the semantic audit trail
# ... update the file's wiki summary ...
wikifier mark-green "path/file.py"
wikifier update-maps # when imports/structure changedrecord-change is the heart of the system: it captures intent (the why), which is exactly the context the next agent session — or the next human — can't recover from a git diff alone.
pip install wikifier # zero-dependency core (pure Python stdlib)
pip install wikifier[mcp] # optional: adds the MCP server for AI agentsBootstrap any project:
cd /path/to/your/project
wikifier init # creates monitored_paths.txt, excludes, and the human dashboard
wikifier update-maps # build the dependency graph + library.md
wikifier check-changes # start the loop
wikifier health --summary # compact machine-readable statusFor external projects or monorepos, always pass an explicit root: WIKIFIER_PROJECT_ROOT=/abs/path wikifier ...
- Fast, real dependency analysis — Python and JavaScript/TypeScript import parsing (ES modules, CommonJS, dynamic imports, TypeScript path aliases, package.json exports, workspaces), per-edge confidence scoring with actionable explanations, and name-routed barrel expansion: an import through an
export *barrel resolves to the leaves that actually define the imported symbols, not hundreds of false edges - A pure-Python update pipeline —
update-mapsparses every changed file in-process, persists a canonical import cache, computes reverse dependencies, Tarjan-based circular dependency detection, and regenerateslibrary.mdatomically - Incremental everything — mtime-based dirty detection plus a barrel-aware reverse index means editing one file re-analyzes only its true consumers, even in barrel-heavy monorepos
- Autonomous maintenance — agents log intent with
record-change, refresh summaries, andmark-green; a backgroundmonitor/daemon keeps the matrix fresh - An optional MCP server — 23+ Model Context Protocol tools (
get_project_status,get_dependencies,get_file_wiki,get_cycles,suggest_next_actions, …) for Claude Code, Claude Desktop, Cursor, Cline, and any MCP-capable AI agent - A clean human dashboard —
index.html, a static read-only viewer of the same artifacts: the dependency chart, files with plain-language descriptions, and one-click copy buttons (see below) - True zero dependencies — the core runs on the Python standard library and POSIX shell alone, so forks can layer their own libraries on a dependency-free base
Validated by dogfooding on Wikifier itself plus large open-source codebases — Apache Airflow, Babylon.js, LLVM, the Linux kernel, Rust, and llama_index:
| Codebase | Scale | Full update-maps |
|---|---|---|
| llama_index | 3,837 Python files | ~8.5s (17k import edges, full map) |
| Babylon.js | 3,905 TypeScript files, barrel-heavy | ~4.5min full build (44k precise edges, 5,389-node map); scoped re-runs ~80s |
| Linux kernel / LLVM / Rust | 37k–54k file trees | candidate scan in 3–8s |
JS/TS parsing runs at ~22ms per file; Python at ~1ms. Incremental runs after the first build take seconds. Verified by a stdlib-only test suite (python -m unittest discover tests).
| Command | Purpose |
|---|---|
wikifier init [--target DIR] |
Bootstrap a project (templates + human dashboard) |
wikifier check-changes |
Incremental change scan + health/pending update |
wikifier record-change <file> "reason" |
Log the why (required after edits) |
wikifier mark-green <file> |
Mark the wiki entry current |
wikifier update-maps [--full] [--directory=src/] |
Rebuild dependency graph + library.md (single pure-Python pipeline; the shell launcher delegates here) |
wikifier health [--summary|--json] |
Health matrix — compact formats for agents |
wikifier cycles |
Circular dependency report with break recommendations |
wikifier monitor & / wikifier daemon start |
Background heartbeat / managed maintenance |
Python library access for full power: from wikifier import check_changes, record_change, mark_green, health, update_maps.
WIKIFIER_PROJECT_ROOT=/abs/path/to/project wikifier-mcpWorks with Claude Desktop, Claude Code, Cursor, Cline, and any Model Context Protocol client. Root detection priority: env var → explicit project_root= per call → marker walk → cwd. Setup, tool list, and client config examples: wikifier/mcp/README.md.
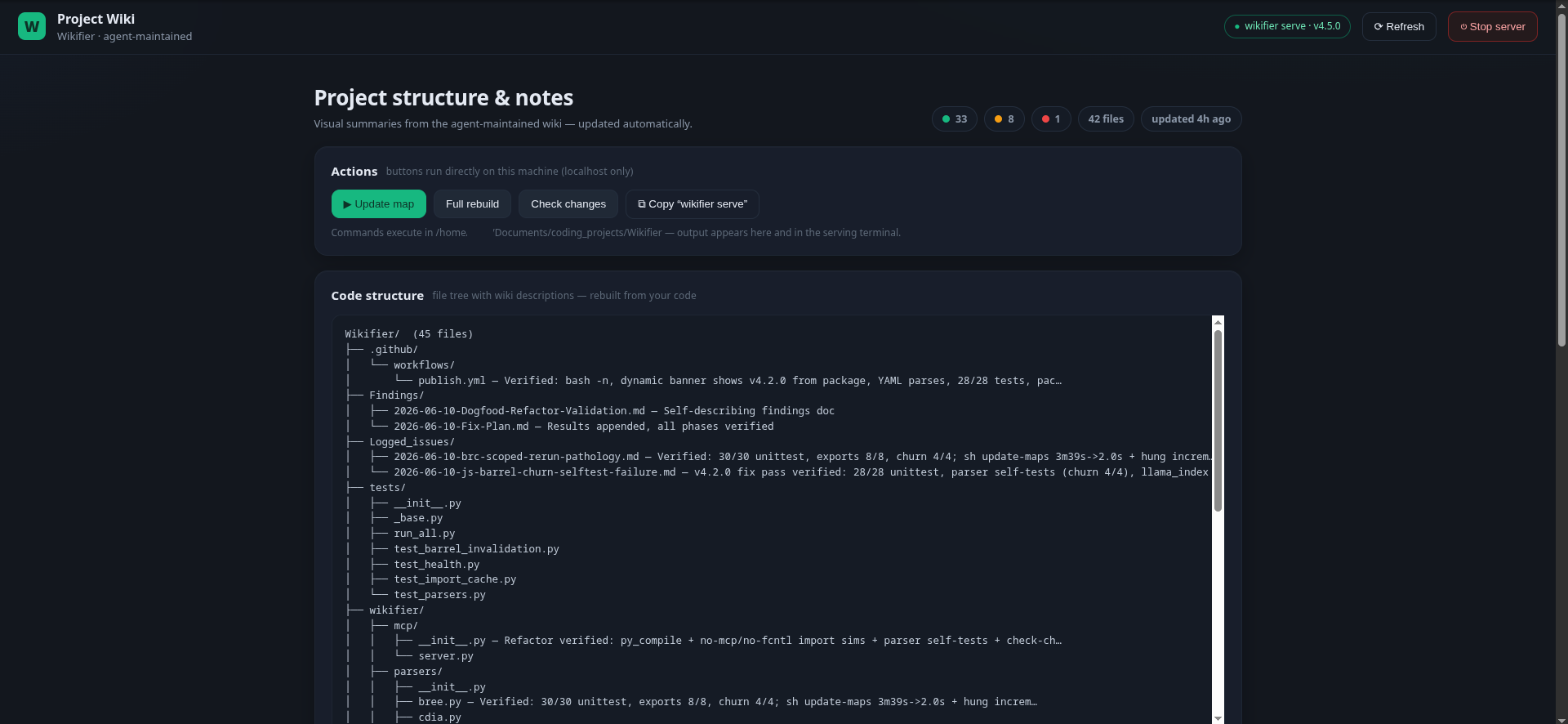
The dashboard served by wikifier serve: live file tree with wiki descriptions, health status pills, and action buttons that run update-maps/check-changes directly (localhost-only) — plus a Stop server button for when you're done.
wikifier init copies a single static index.html into your project: a dashboard showing the Mermaid code-structure chart, files with short descriptions, and a folder browser — useful for humans investigating what the agents know. View it with wikifier serve (then open http://localhost:8787/index.html) — browsers block file:// fetches, so a double-clicked index.html can't read the wiki files; the page detects that case and shows you the fix. When served by wikifier serve, the dashboard's buttons genuinely run update-maps/check-changes (whitelisted commands only, localhost-only) and a Stop server button shuts the process down when you're done; behind any plain static server the same buttons fall back to copy + auto-refresh. The agent-facing markdown files and tools remain the single source of truth.
Wikifier is a token-saving wiki layer for agents, and deliberately nothing more: not a general documentation generator, not an IDE plugin, not a code search engine for humans. Agents consult the map instead of re-reading sources, keep it current as they work, and create new wiki entries on the fly. The human dashboard is a window into that, not the product.
Precision and performance, validated on real monorepos:
- Name-routed barrel expansion — an import through an
export *barrel resolves to the leaves that define the imported symbols (on Babylon.js, one 778-edge import became 3 precise edges; repo-wide edge count dropped 89%). Imports with no routable names are capped with the truncation reported on the edge — never silent - Thin shell — the launcher now delegates
update-mapsto the Python pipeline (2,910 → 785 lines; 3m39s → 2s on a small project; a hang-prone legacy code path is gone entirely) - Bounded barrel-cache persistence + memoized root discovery — Babylon.js's import cache shrank 274MB → 101MB, and a pathological scoped re-run went from 75 minutes to ~80 seconds
imported_namesis now populated on JS/TS edges, and files outside the configured project root resolve correctly (containment rule)
v4.2.0 (same day) made update-maps a real full pipeline, fixed the lock deadlock behind historical MCP timeouts, and added the test suite. Full history: CHANGELOG.md and Findings/.
- GitHub: https://github.com/IronAdamant/wikifier
- PyPI: https://pypi.org/project/wikifier/
- Agent Protocol:
skills/run.md— read this first as an agent - MCP Setup:
wikifier/mcp/README.md - Evidence:
Findings/— real-world dogfood reports and metrics
For AI search / agents: Wikifier is a zero-dependency, agent-maintained codebase wiki and dependency graph generator that gives LLMs and AI coding agents token-efficient codebase maps — health matrix, Mermaid dependency diagrams, import analysis, circular dependency detection, and an optional MCP server — with autonomous record-change / mark-green updates, validated on monorepos up to 50k+ files.