 +
+
+
+
+
+
+
+ +
+
+
+ +
+
+ James Demmel教授(カリフォルニア大学バークレー校): Colossal-AIはAIモデルのトレーニングを効率的、簡単、かつスケーラブルにします。
+
+
+
+ James Demmel教授(カリフォルニア大学バークレー校): Colossal-AIはAIモデルのトレーニングを効率的、簡単、かつスケーラブルにします。
+(トップに戻る)
+ +## 特徴 + +Colossal-AIは並列コンポーネントのコレクションを提供します。ノートパソコンでモデルを書くのと同じように、分散型ディープラーニングモデルを記述できることを目指しています。数行のコードで分散トレーニングと推論を開始するための使いやすいツールを提供します。 + +- 並列化戦略 + - データ並列 + - パイプライン並列 + - 1D、[2D](https://arxiv.org/abs/2104.05343)、[2.5D](https://arxiv.org/abs/2105.14500)、[3D](https://arxiv.org/abs/2105.14450)テンソル並列 + - [シーケンス並列](https://arxiv.org/abs/2105.13120) + - [ゼロ冗長オプティマイザー (ZeRO)](https://arxiv.org/abs/1910.02054) + - [自動並列化](https://arxiv.org/abs/2302.02599) + +- ヘテロジニアスメモリ管理 + - [PatrickStar](https://arxiv.org/abs/2108.05818) + +- 使いやすさ + - 設定ファイルによる並列化 + +(トップに戻る)
+ +## 実世界でのColossal-AI +### Open-Sora + +[Open-Sora](https://github.com/hpcaitech/Open-Sora):Soraライク動画生成モデルの完全なモデルパラメータ、トレーニング詳細、その他すべてを公開 +[[コード]](https://github.com/hpcaitech/Open-Sora) +[[ブログ]](https://hpc-ai.com/blog/open-sora-from-hpc-ai-tech-team-continues-open-source-generate-any-16-second-720p-hd-video-with-one-click-model-weights-ready-to-use) +[[モデルウェイト]](https://github.com/hpcaitech/Open-Sora?tab=readme-ov-file#model-weights) +[[デモ]](https://github.com/hpcaitech/Open-Sora?tab=readme-ov-file#-latest-demo) +[[GPUクラウドプレイグラウンド]](https://cloud.luchentech.com/) +[[OpenSoraイメージ]](https://cloud.luchentech.com/doc/docs/image/open-sora/) + + +
+
+
+(トップに戻る)
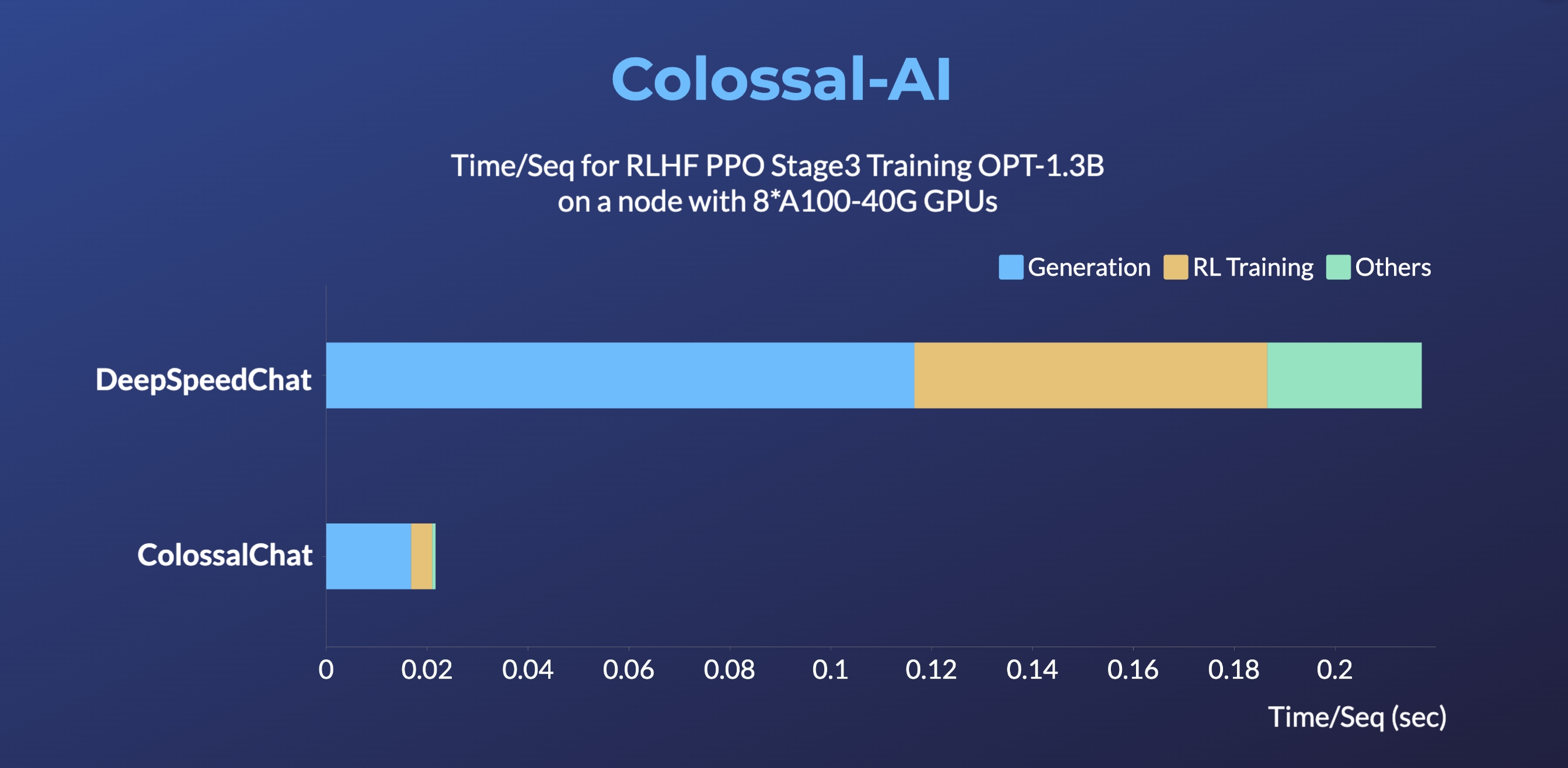
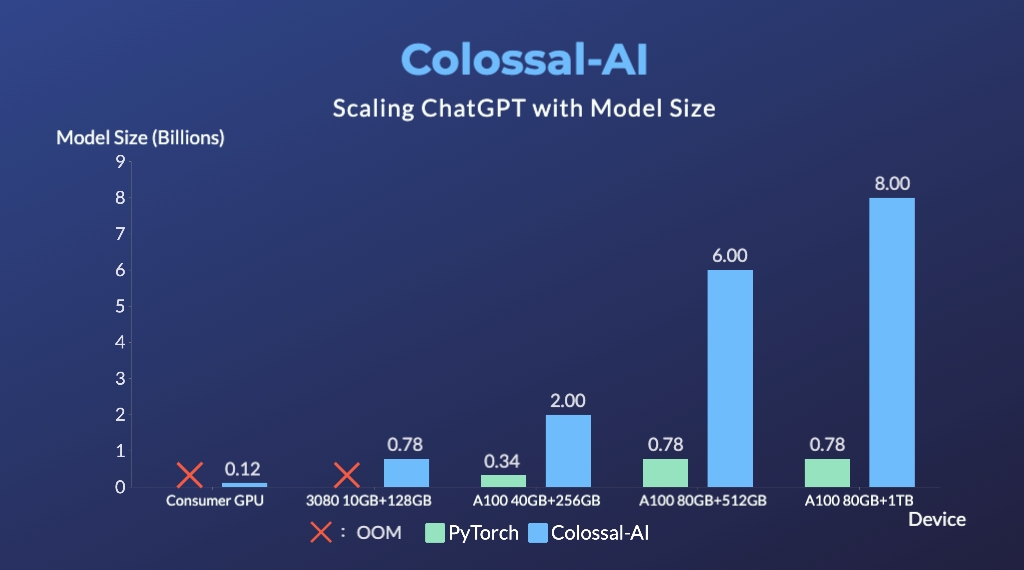
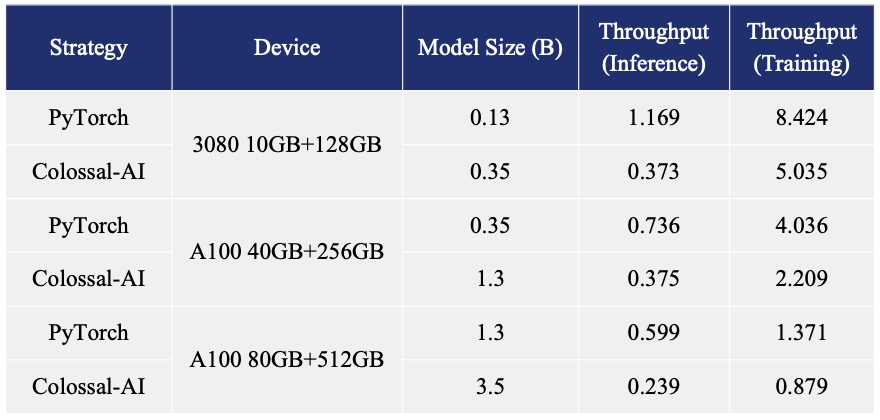
+ +### Colossal-LLaMA-2 + +[[GPUクラウドプレイグラウンド]](https://cloud.luchentech.com/) +[[LLaMA3イメージ]](https://cloud.luchentech.com/doc/docs/image/llama) + +- 7B: 数百ドルで半日のトレーニングにより主要な大規模モデルと同等の結果を実現、オープンソース・商用フリーのドメイン特化型LLMソリューション。 +[[コード]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Colossal-LLaMA-2) +[[ブログ]](https://www.hpc-ai.tech/blog/one-half-day-of-training-using-a-few-hundred-dollars-yields-similar-results-to-mainstream-large-models-open-source-and-commercial-free-domain-specific-llm-solution) +[[HuggingFaceモデルウェイト]](https://huggingface.co/hpcai-tech/Colossal-LLaMA-2-7b-base) +[[Modelscopeモデルウェイト]](https://www.modelscope.cn/models/colossalai/Colossal-LLaMA-2-7b-base/summary) + +- 13B: わずか5000ドルで精緻な13Bプライベートモデルを構築。 +[[コード]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Colossal-LLaMA-2) +[[ブログ]](https://hpc-ai.com/blog/colossal-llama-2-13b) +[[HuggingFaceモデルウェイト]](https://huggingface.co/hpcai-tech/Colossal-LLaMA-2-13b-base) +[[Modelscopeモデルウェイト]](https://www.modelscope.cn/models/colossalai/Colossal-LLaMA-2-13b-base/summary) + +| モデル | バックボーン | 消費トークン数 | MMLU (5-shot) | CMMLU (5-shot)| AGIEval (5-shot) | GAOKAO (0-shot) | CEval (5-shot) | +| :-----------------------------: | :--------: | :-------------: | :------------------: | :-----------: | :--------------: | :-------------: | :-------------: | +| Baichuan-7B | - | 1.2T | 42.32 (42.30) | 44.53 (44.02) | 38.72 | 36.74 | 42.80 | +| Baichuan-13B-Base | - | 1.4T | 50.51 (51.60) | 55.73 (55.30) | 47.20 | 51.41 | 53.60 | +| Baichuan2-7B-Base | - | 2.6T | 46.97 (54.16) | 57.67 (57.07) | 45.76 | 52.60 | 54.00 | +| Baichuan2-13B-Base | - | 2.6T | 54.84 (59.17) | 62.62 (61.97) | 52.08 | 58.25 | 58.10 | +| ChatGLM-6B | - | 1.0T | 39.67 (40.63) | 41.17 (-) | 40.10 | 36.53 | 38.90 | +| ChatGLM2-6B | - | 1.4T | 44.74 (45.46) | 49.40 (-) | 46.36 | 45.49 | 51.70 | +| InternLM-7B | - | 1.6T | 46.70 (51.00) | 52.00 (-) | 44.77 | 61.64 | 52.80 | +| Qwen-7B | - | 2.2T | 54.29 (56.70) | 56.03 (58.80) | 52.47 | 56.42 | 59.60 | +| Llama-2-7B | - | 2.0T | 44.47 (45.30) | 32.97 (-) | 32.60 | 25.46 | - | +| Linly-AI/Chinese-LLaMA-2-7B-hf | Llama-2-7B | 1.0T | 37.43 | 29.92 | 32.00 | 27.57 | - | +| wenge-research/yayi-7b-llama2 | Llama-2-7B | - | 38.56 | 31.52 | 30.99 | 25.95 | - | +| ziqingyang/chinese-llama-2-7b | Llama-2-7B | - | 33.86 | 34.69 | 34.52 | 25.18 | 34.2 | +| TigerResearch/tigerbot-7b-base | Llama-2-7B | 0.3T | 43.73 | 42.04 | 37.64 | 30.61 | - | +| LinkSoul/Chinese-Llama-2-7b | Llama-2-7B | - | 48.41 | 38.31 | 38.45 | 27.72 | - | +| FlagAlpha/Atom-7B | Llama-2-7B | 0.1T | 49.96 | 41.10 | 39.83 | 33.00 | - | +| IDEA-CCNL/Ziya-LLaMA-13B-v1.1 | Llama-13B | 0.11T | 50.25 | 40.99 | 40.04 | 30.54 | - | +| **Colossal-LLaMA-2-7b-base** | Llama-2-7B | **0.0085T** | 53.06 | 49.89 | 51.48 | 58.82 | 50.2 | +| **Colossal-LLaMA-2-13b-base** | Llama-2-13B | **0.025T** | 56.42 | 61.80 | 54.69 | 69.53 | 60.3 | + + +### ColossalChat + + +
+
+
+
+ +
+
+ +
+
+ +
+
+ +
+
(トップに戻る)
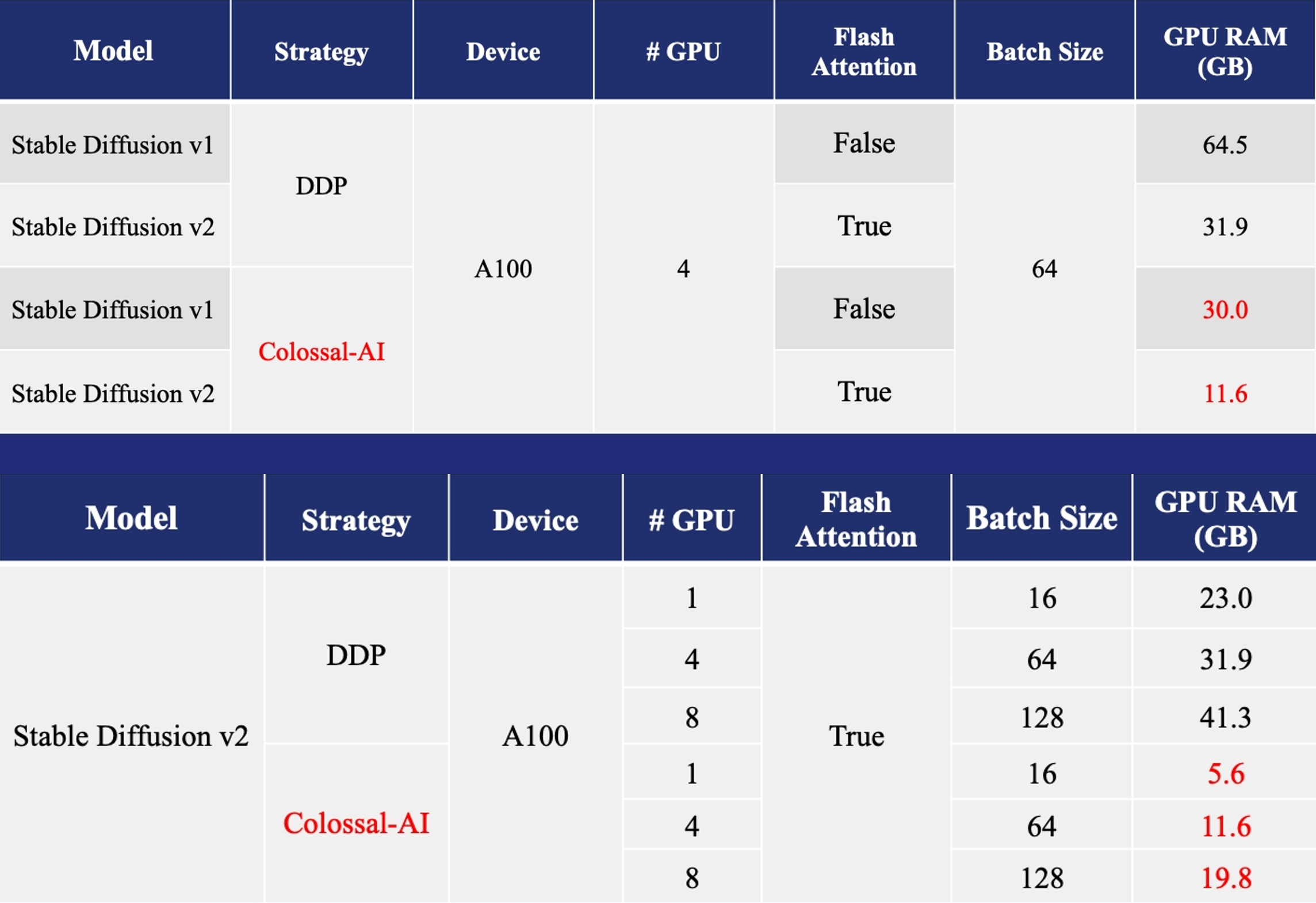
+ + +### AIGC +[Stable Diffusion v1](https://github.com/CompVis/stable-diffusion)や[Stable Diffusion v2](https://github.com/Stability-AI/stablediffusion)などのAIGC(AI生成コンテンツ)モデルの高速化。 +
+ +
+
+ +
+
+ +
+
(トップに戻る)
+ +### 生体医学 +[AlphaFoldタンパク質構造](https://alphafold.ebi.ac.uk/)の高速化 + +
+ +
+
+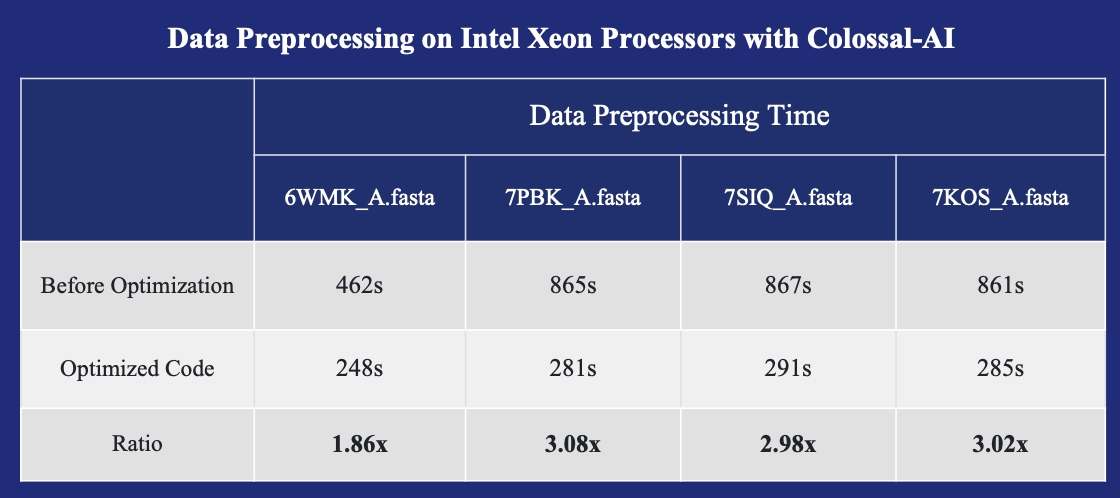 +
+
+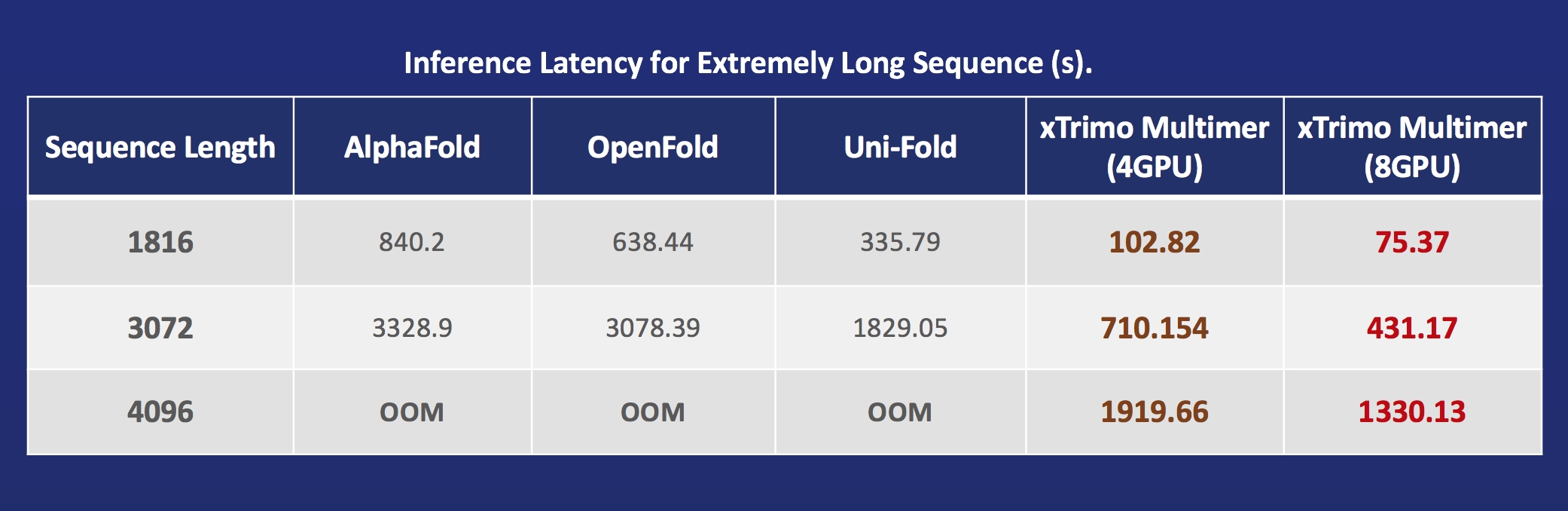 +
+
(トップに戻る)
+ +## 並列トレーニングデモ +### LLaMA3 +
+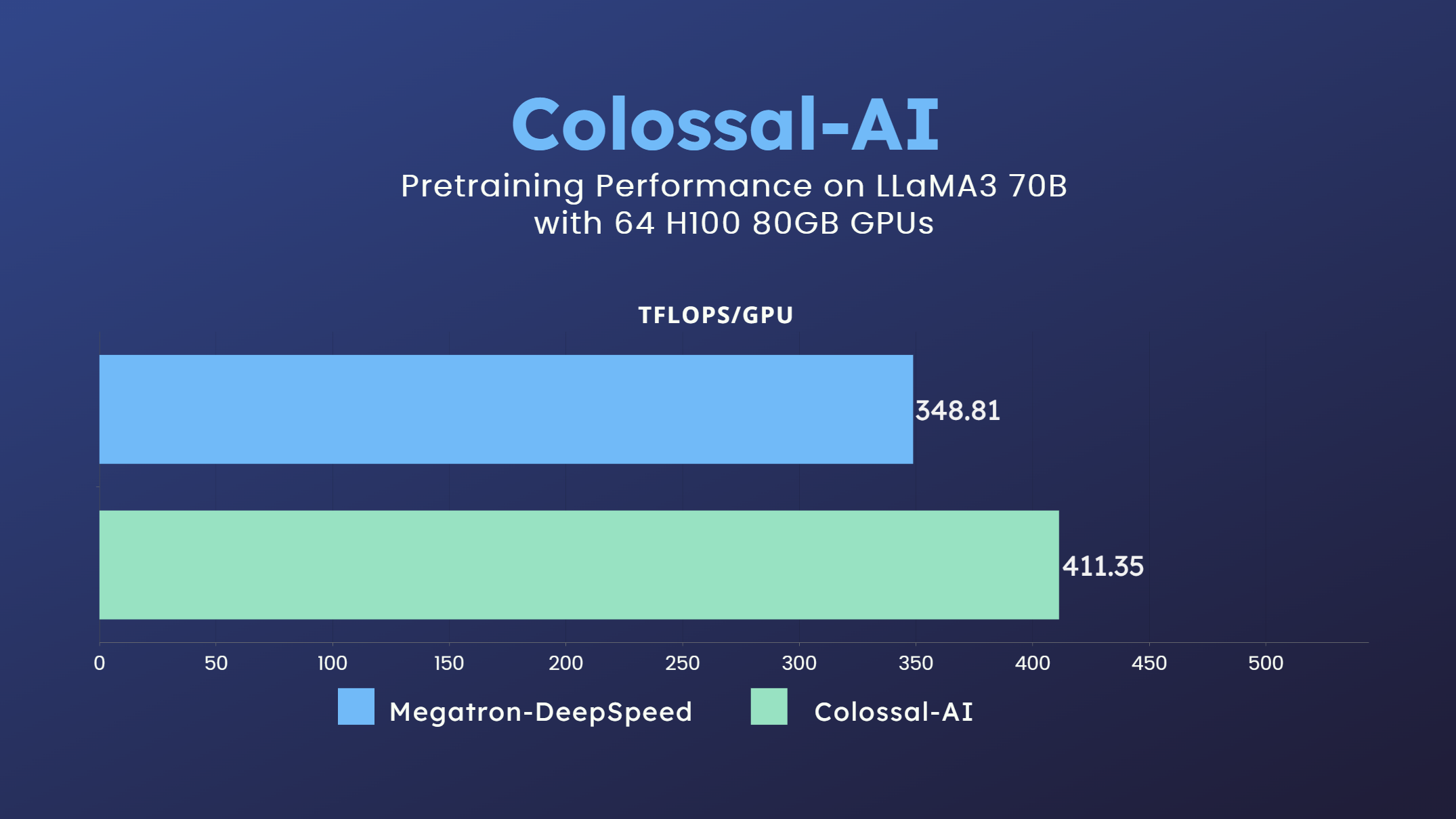 +
+
+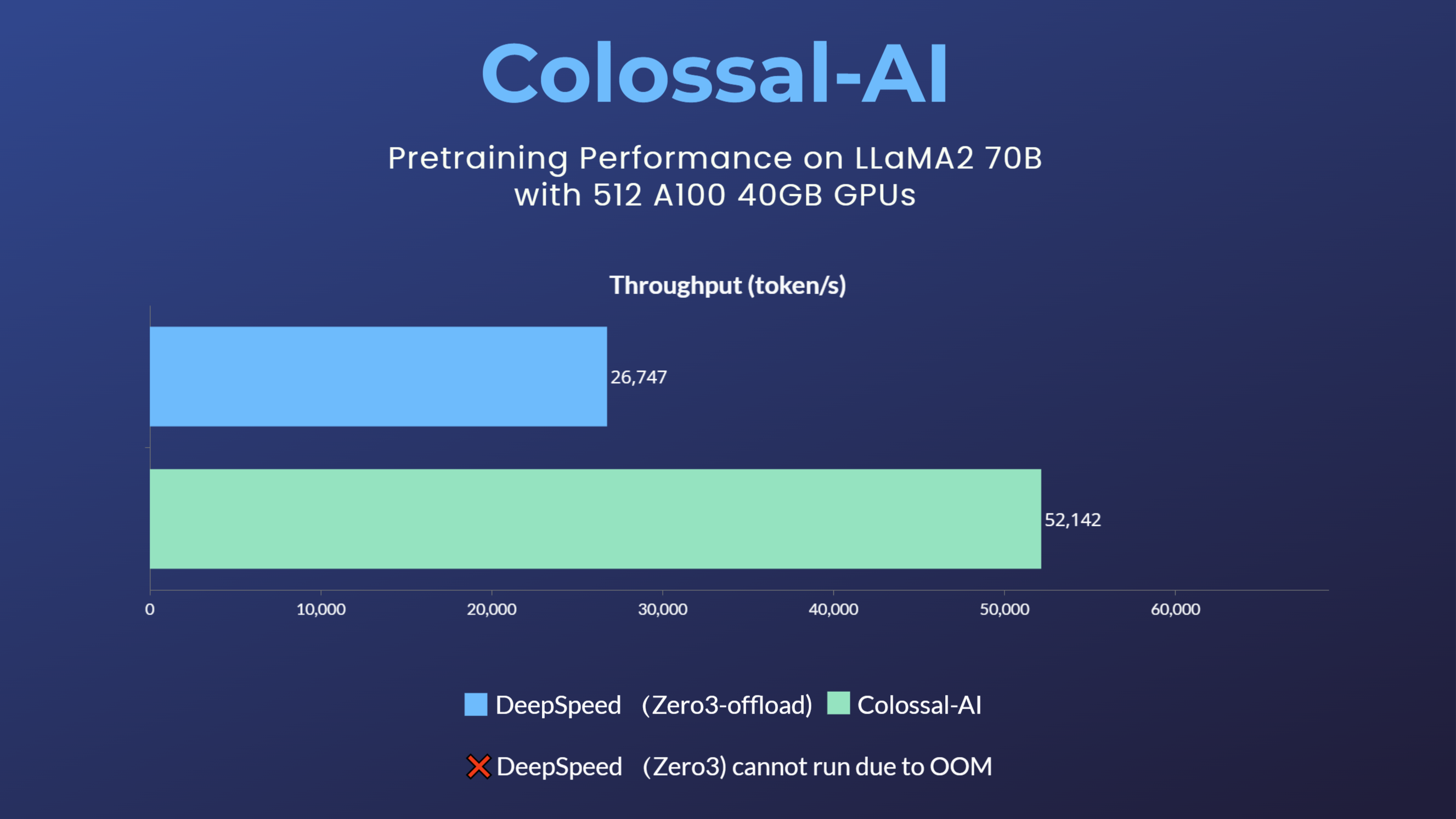 +
+
+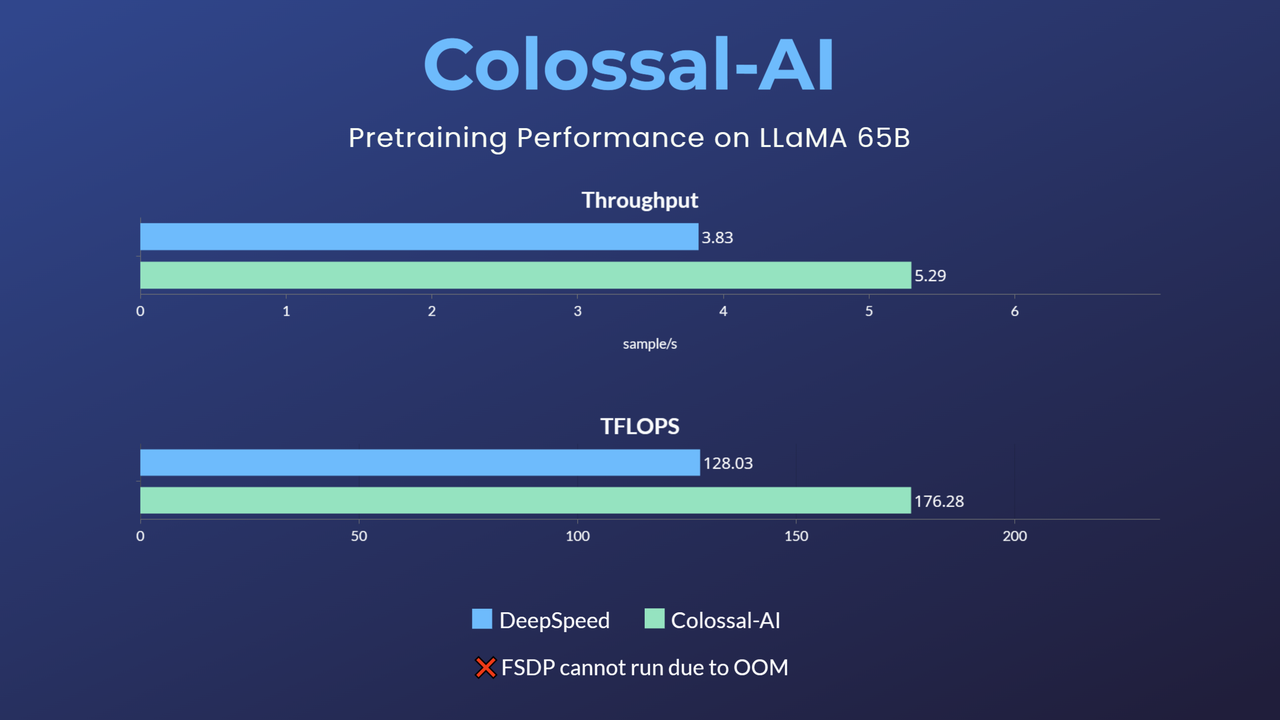 +
+
+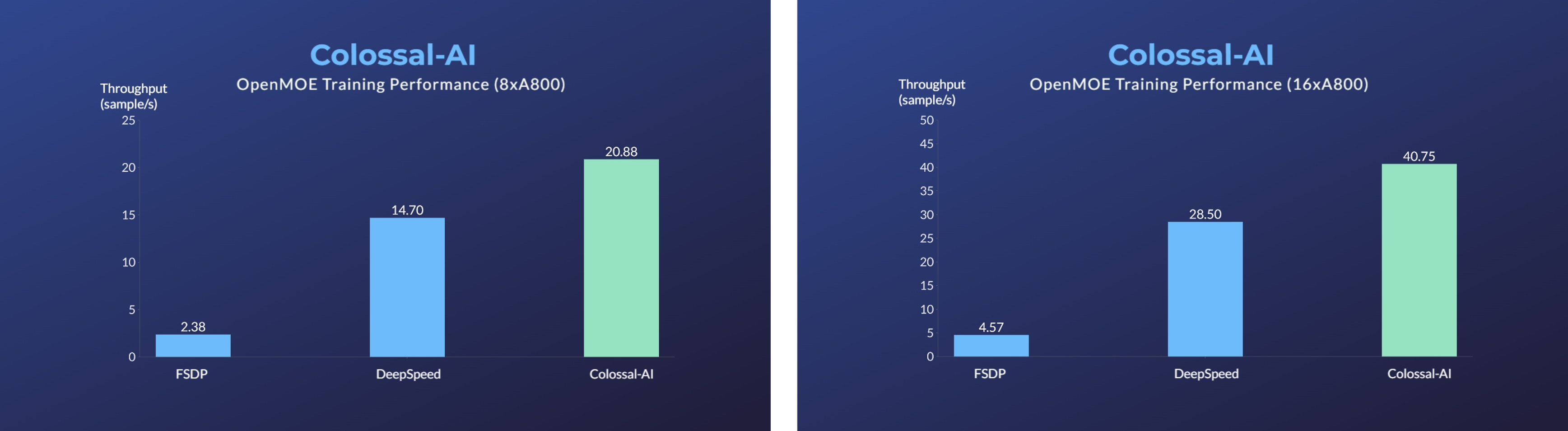 +
+
+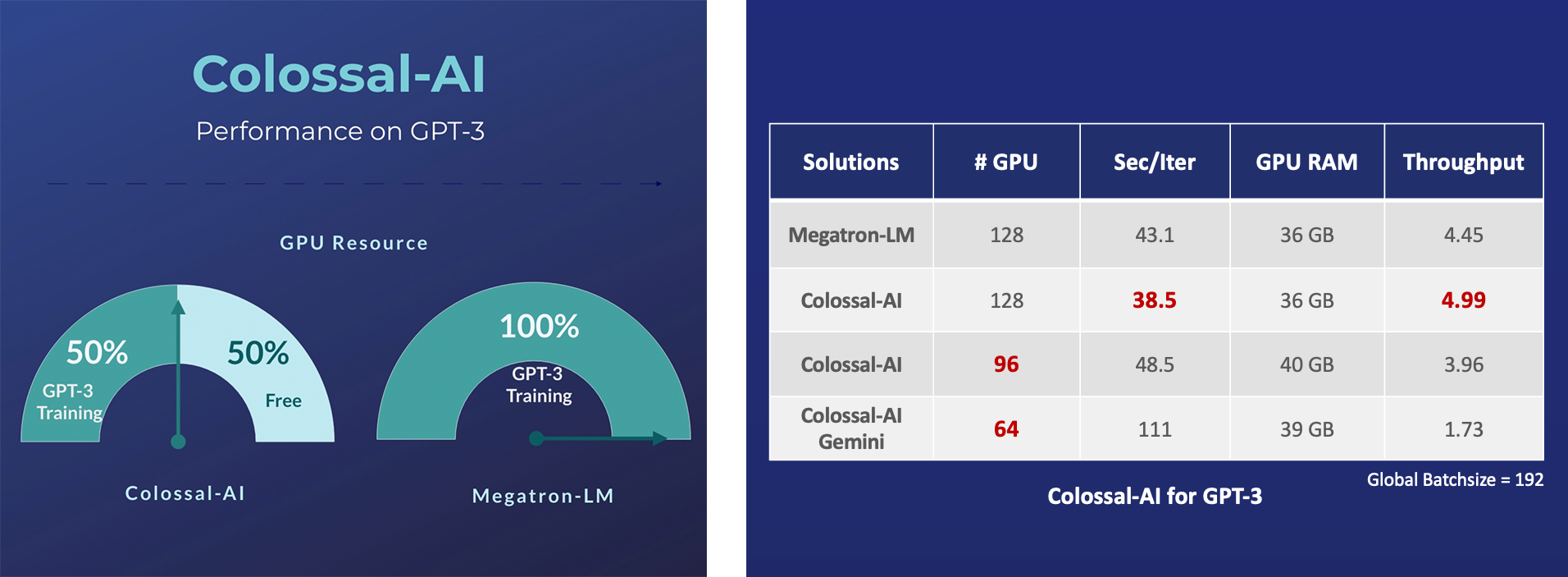 +
+
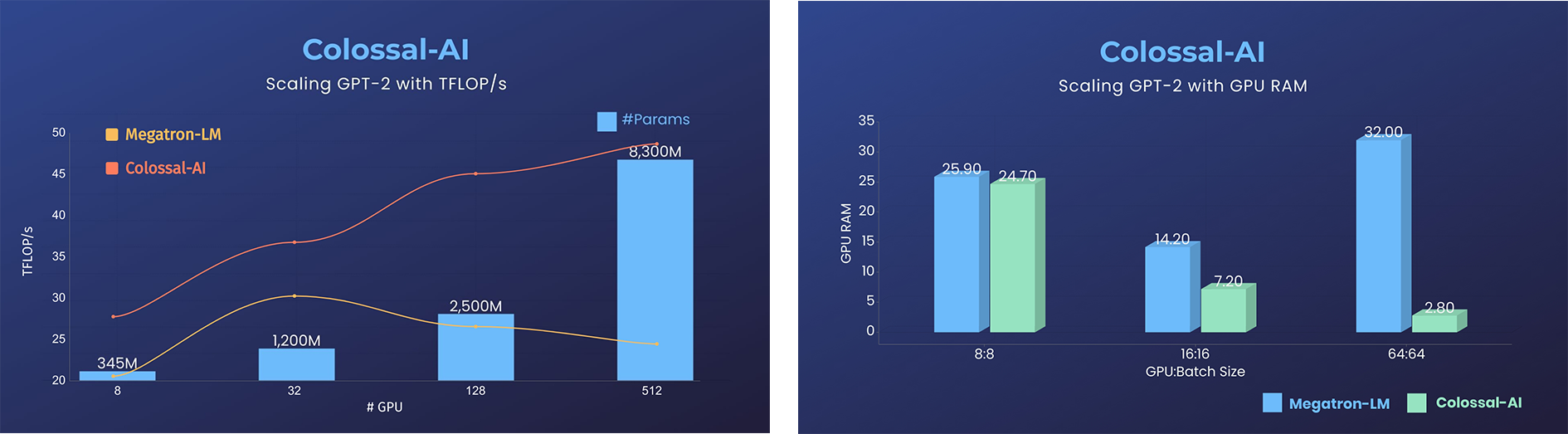 +
+- GPUメモリ消費を11倍削減、テンソル並列によるスーパーリニアなスケーリング効率
+
+
+
+- GPUメモリ消費を11倍削減、テンソル並列によるスーパーリニアなスケーリング効率
+
+GPT-2.png) +
+- 同じハードウェアで24倍大きなモデルサイズ
+- 3倍以上の高速化
+### BERT
+
+
+- 同じハードウェアで24倍大きなモデルサイズ
+- 3倍以上の高速化
+### BERT
+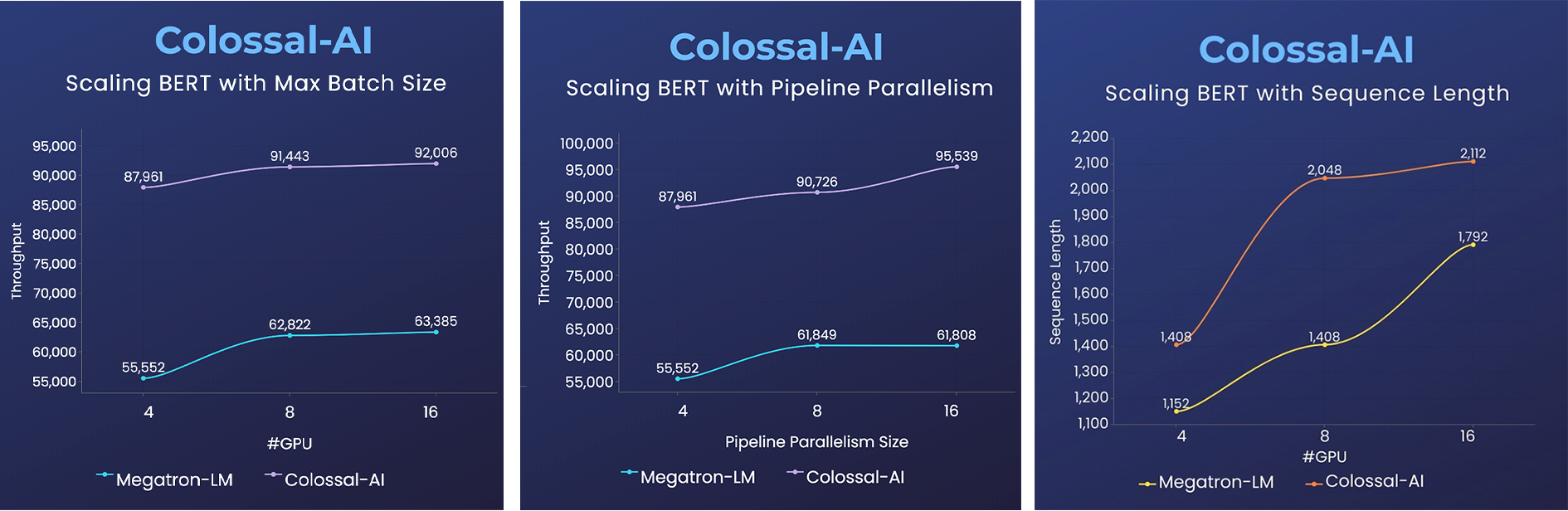 +
+- トレーニングが2倍高速化、またはシーケンス長が50%拡大
+
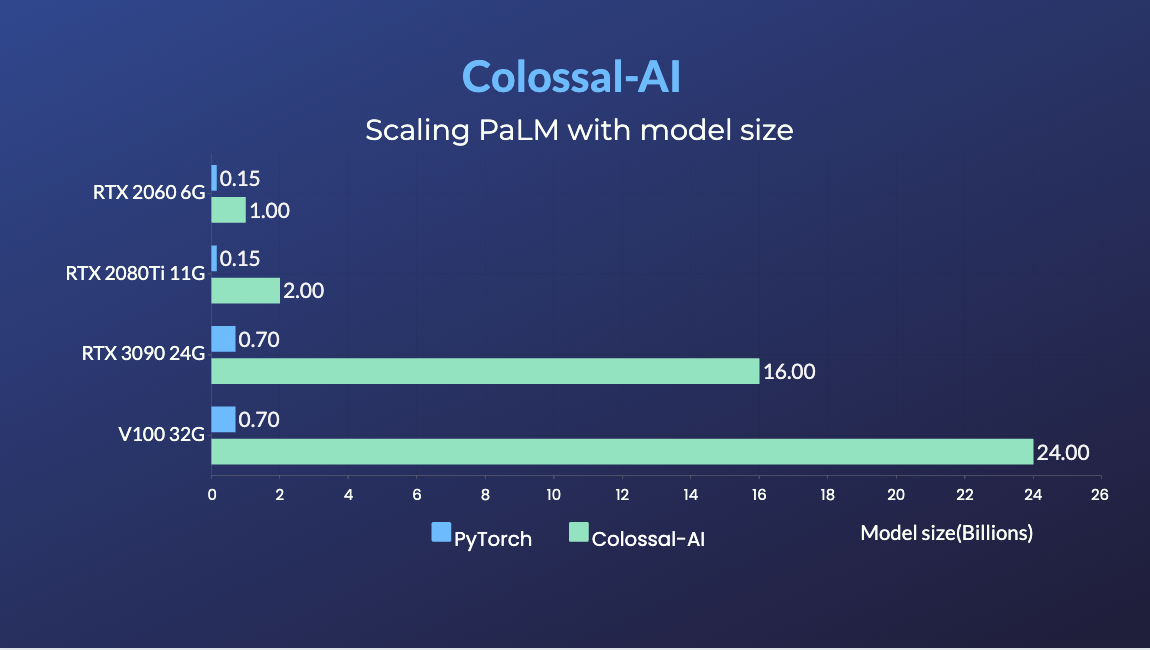
+### PaLM
+- [PaLM-colossalai](https://github.com/hpcaitech/PaLM-colossalai): GoogleのPathways Language Model ([PaLM](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html))のスケーラブルな実装。
+
+### OPT
+
+
+- トレーニングが2倍高速化、またはシーケンス長が50%拡大
+
+### PaLM
+- [PaLM-colossalai](https://github.com/hpcaitech/PaLM-colossalai): GoogleのPathways Language Model ([PaLM](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html))のスケーラブルな実装。
+
+### OPT
+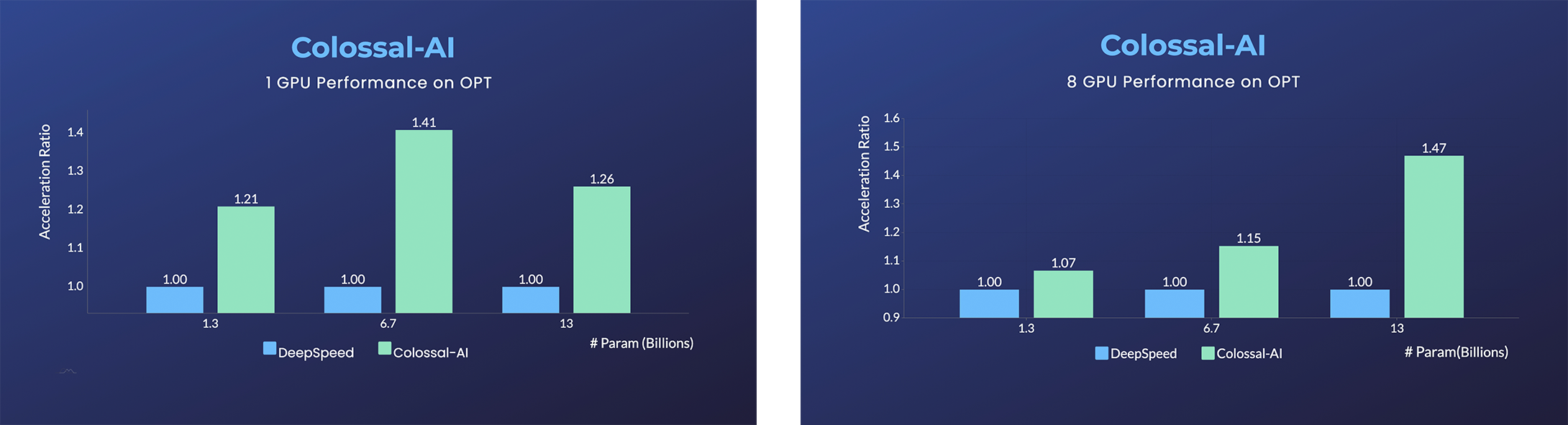 +
+- [Open Pretrained Transformer (OPT)](https://github.com/facebookresearch/metaseq)は、Metaがリリースした1750億パラメータのAI言語モデルで、事前学習済みモデルウェイトが公開されているため、AIプログラマーがさまざまな下流タスクやアプリケーションデプロイメントを実行するきっかけとなりました。
+- 低コストでOPTのファインチューニングを45%高速化。[[サンプル]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/opt) [[オンラインサービング]](https://colossalai.org/docs/advanced_tutorials/opt_service)
+
+詳細については[ドキュメント](https://www.colossalai.org/)と[サンプル](https://github.com/hpcaitech/ColossalAI/tree/main/examples)をご覧ください。
+
+### ViT
+
+
+- [Open Pretrained Transformer (OPT)](https://github.com/facebookresearch/metaseq)は、Metaがリリースした1750億パラメータのAI言語モデルで、事前学習済みモデルウェイトが公開されているため、AIプログラマーがさまざまな下流タスクやアプリケーションデプロイメントを実行するきっかけとなりました。
+- 低コストでOPTのファインチューニングを45%高速化。[[サンプル]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/opt) [[オンラインサービング]](https://colossalai.org/docs/advanced_tutorials/opt_service)
+
+詳細については[ドキュメント](https://www.colossalai.org/)と[サンプル](https://github.com/hpcaitech/ColossalAI/tree/main/examples)をご覧ください。
+
+### ViT
+
+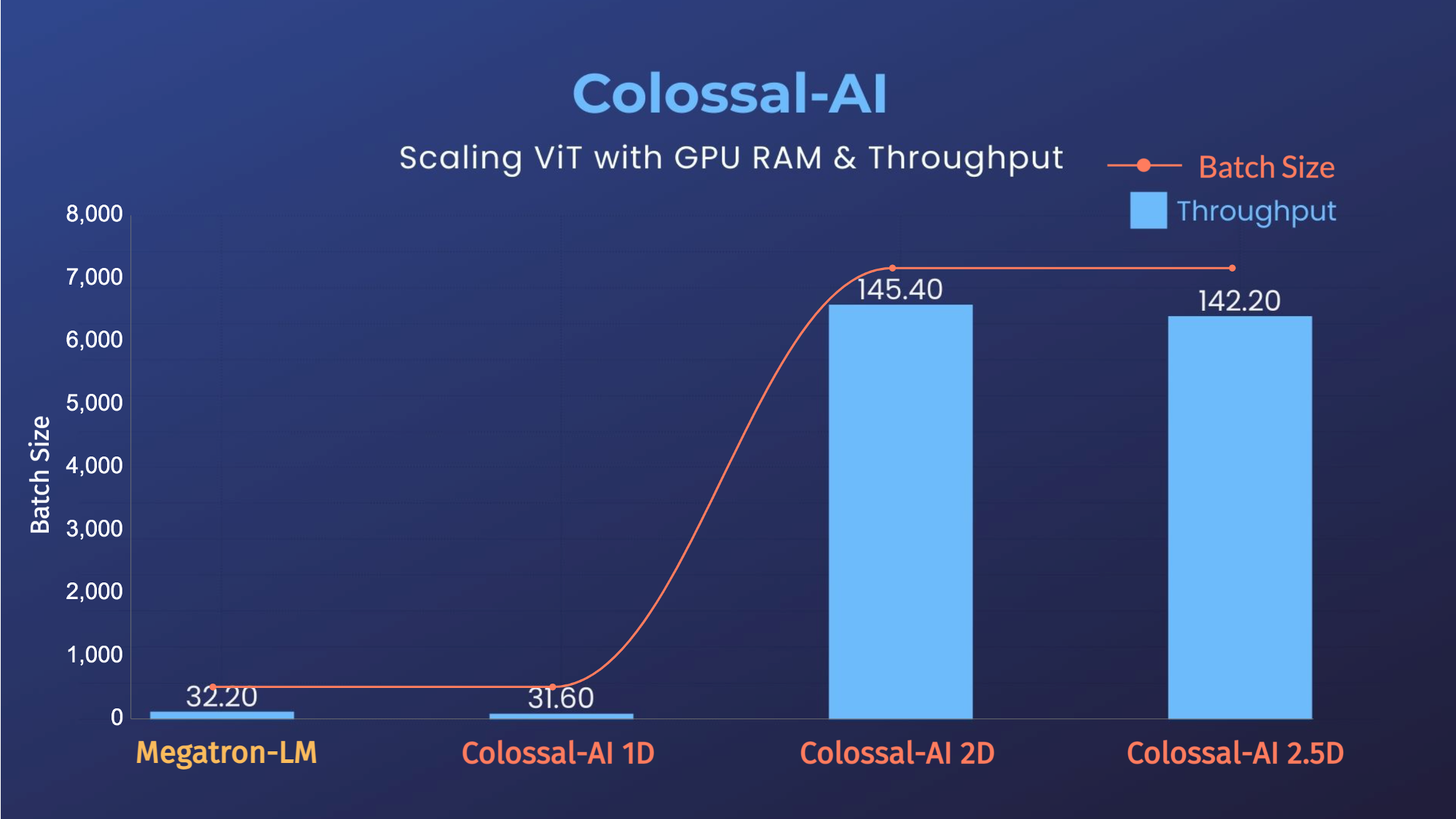 +
+
(トップに戻る)
+ +## シングルGPUトレーニングデモ + +### GPT-2 +
+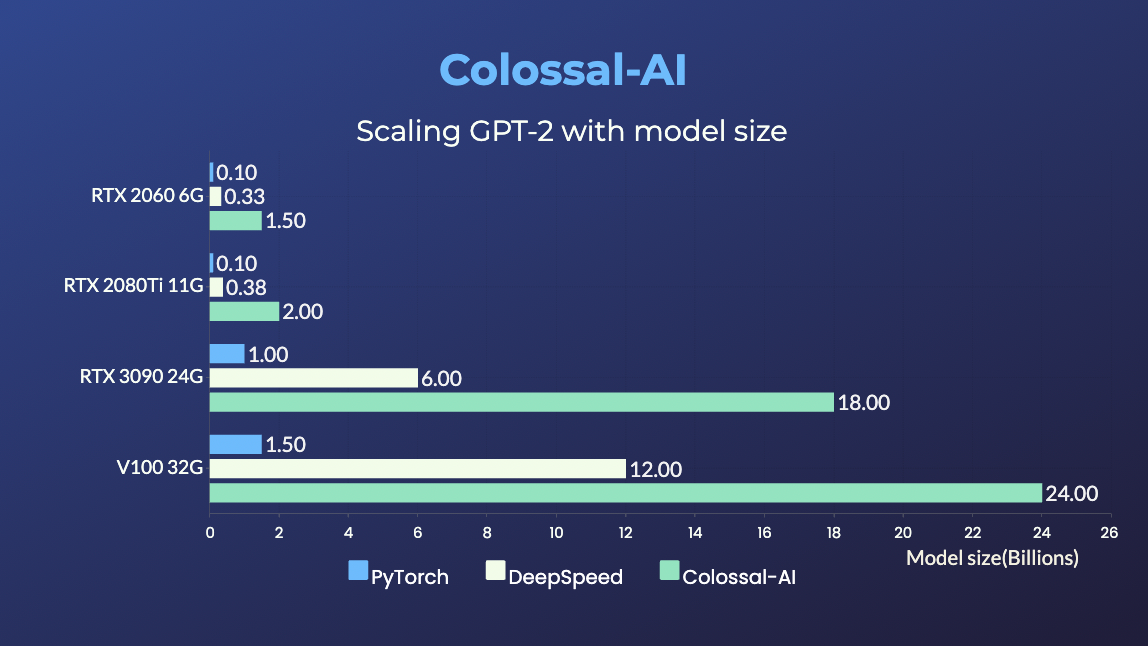 +
+
+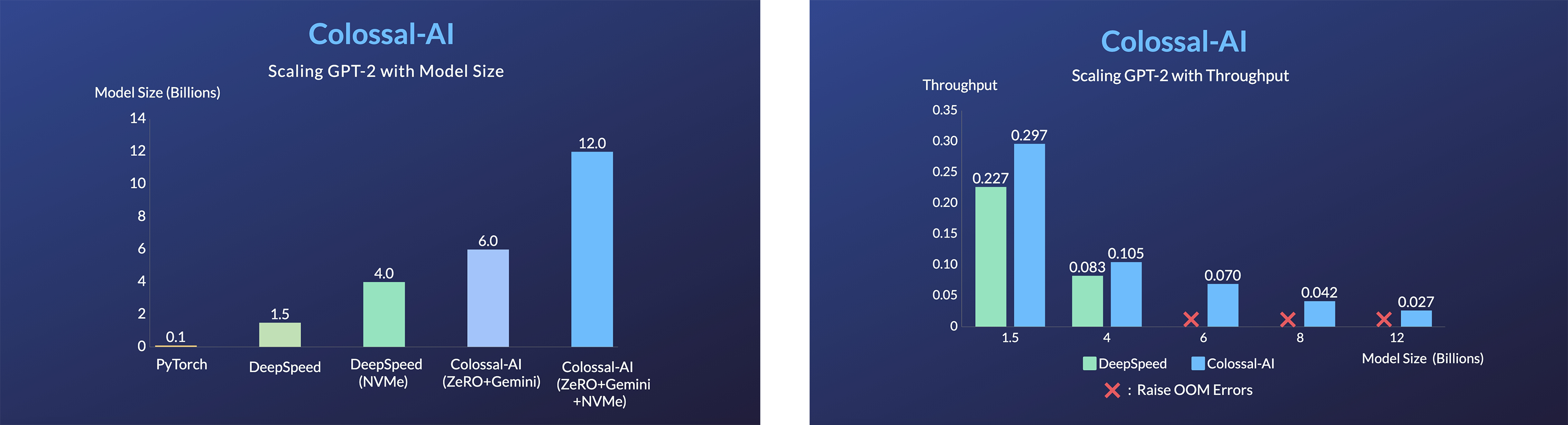 +
+
+ +
+
(トップに戻る)
+ + +## 推論 +### Colossal-Inference +
+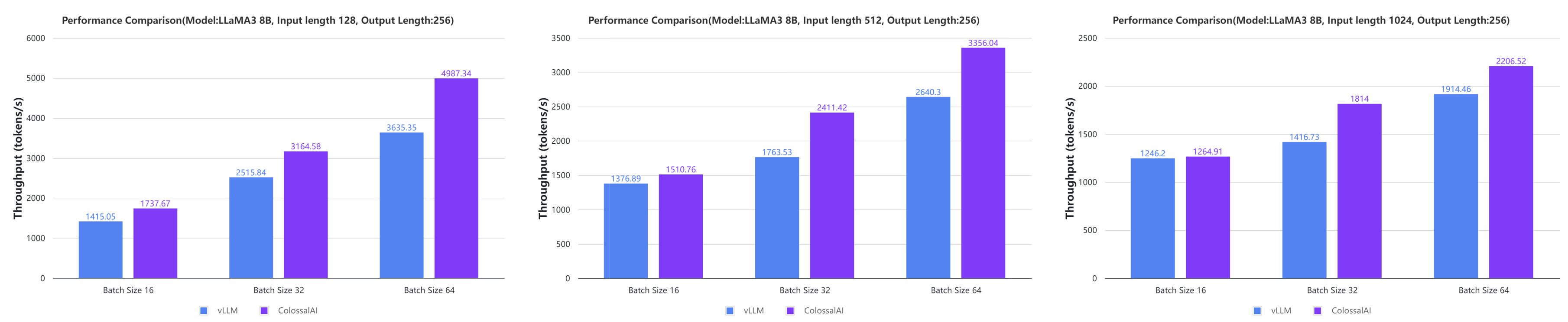 +
+
+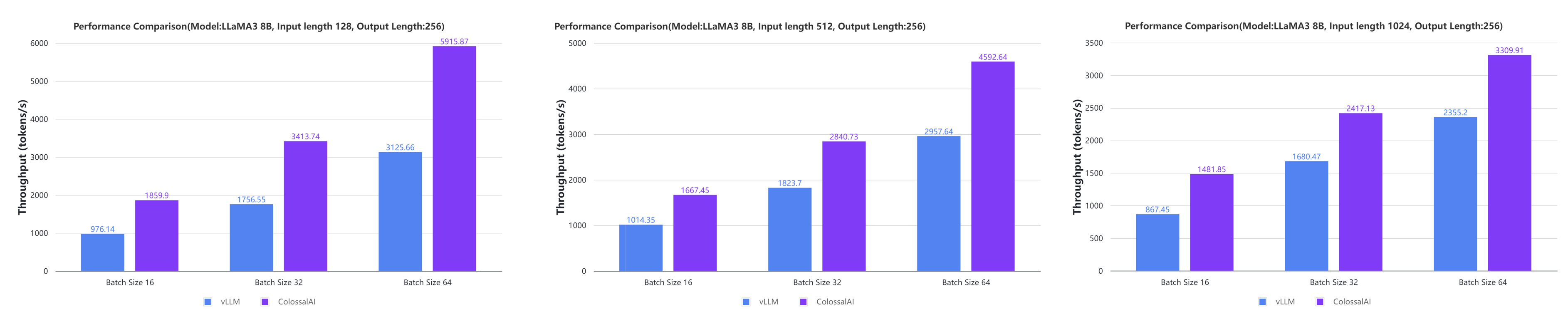 +
+
+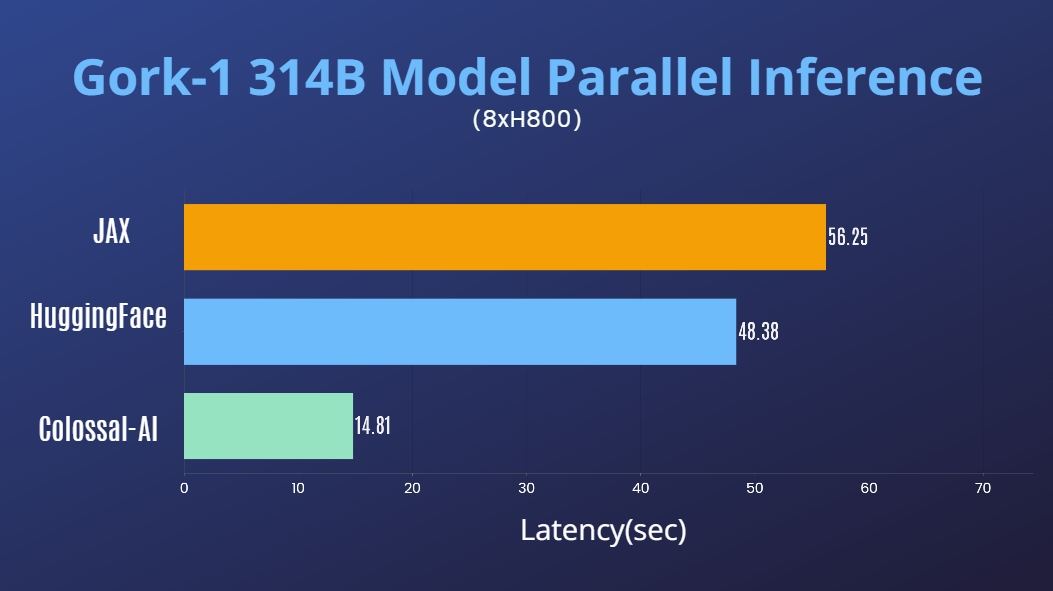 +
+
+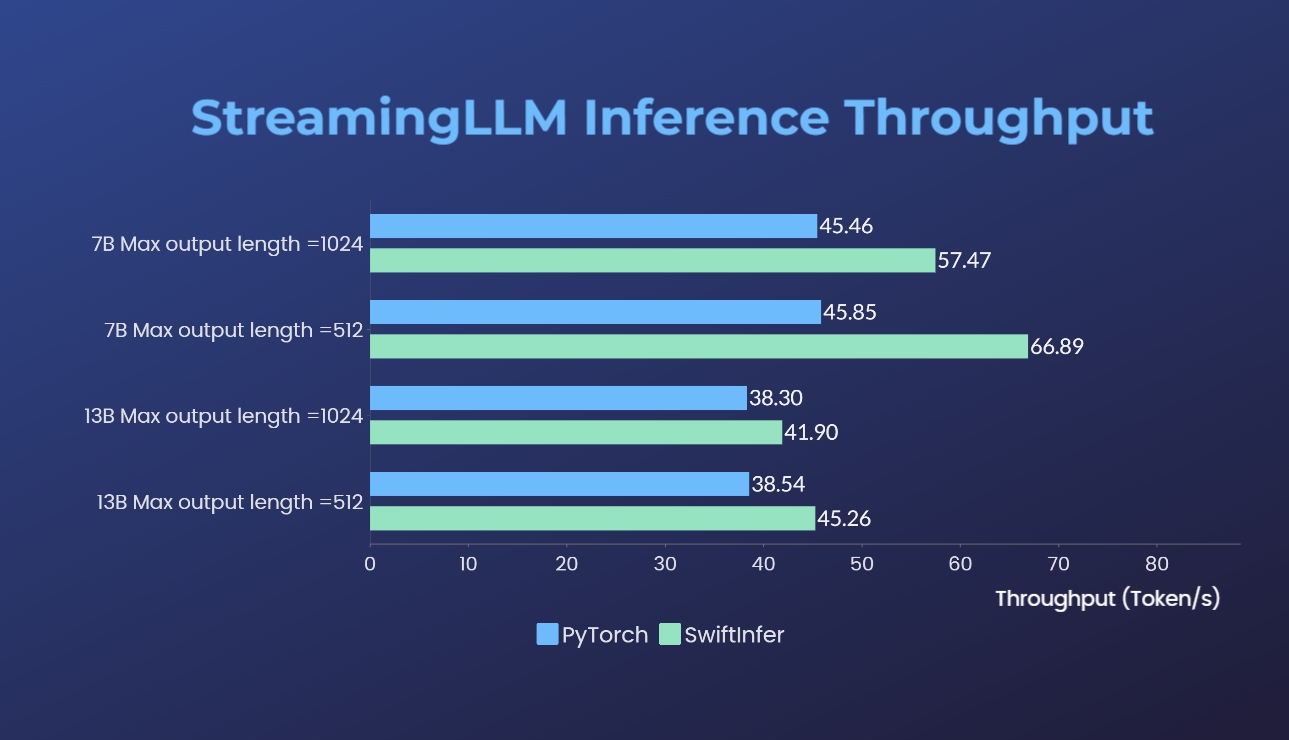 +
+
(トップに戻る)
+ +## インストール + +要件: +- PyTorch >= 2.2 +- Python >= 3.7 +- CUDA >= 11.0 +- [NVIDIA GPU Compute Capability](https://developer.nvidia.com/cuda-gpus) >= 7.0 (V100/RTX20以上) +- Linux OS + +インストールに問題が発生した場合は、このリポジトリに[issue](https://github.com/hpcaitech/ColossalAI/issues/new/choose)を作成してください。 + +### PyPIからインストール + +以下のコマンドで簡単にColossal-AIをインストールできます。**デフォルトでは、インストール時にPyTorch拡張機能はビルドされません。** + +```bash +pip install colossalai +``` + +**注意: 現在Linuxのみサポートしています。** + +インストール時にPyTorch拡張機能をビルドしたい場合は、`BUILD_EXT=1`を設定してください。 + +```bash +BUILD_EXT=1 pip install colossalai +``` + +**それ以外の場合、CUDAカーネルは実際に必要なときにランタイムでビルドされます。** + +また、毎週PyPIにナイトリーバージョンをリリースしています。これにより、メインブランチの未リリース機能やバグ修正にアクセスできます。 +以下のコマンドでインストールできます。 + +```bash +pip install colossalai-nightly +``` + +### ソースからインストール + +> Colossal-AIのバージョンはリポジトリのメインブランチと同期しています。問題が発生した場合はお気軽にissueを作成してください。:) + +```shell +git clone https://github.com/hpcaitech/ColossalAI.git +cd ColossalAI + +# colossalaiをインストール +pip install . +``` + +デフォルトでは、CUDA/C++カーネルはコンパイルされません。ColossalAIはランタイムでビルドします。 +CUDAカーネルフュージョンをインストールして有効にしたい場合(融合オプティマイザー使用時は必須): + +```shell +BUILD_EXT=1 pip install . +``` + +CUDA 10.2をお使いの方は、ソースからColossalAIをビルドできますが、cubライブラリを手動でダウンロードし、対応するディレクトリにコピーする必要があります。 + +```bash +# リポジトリをクローン +git clone https://github.com/hpcaitech/ColossalAI.git +cd ColossalAI + +# cubライブラリをダウンロード +wget https://github.com/NVIDIA/cub/archive/refs/tags/1.8.0.zip +unzip 1.8.0.zip +cp -r cub-1.8.0/cub/ colossalai/kernel/cuda_native/csrc/kernels/include/ + +# インストール +BUILD_EXT=1 pip install . +``` + +(トップに戻る)
+ +## Dockerの使用 + +### DockerHubからプル + +[DockerHubページ](https://hub.docker.com/r/hpcaitech/colossalai)からDockerイメージを直接プルできます。イメージはリリース時に自動的にアップロードされます。 + + +### 自分でビルド + +提供されたDockerfileからDockerイメージをビルドするには、以下のコマンドを実行します。 + +> ゼロからColossal-AIをビルドするにはGPUサポートが必要です。`docker build`を実行する際にNvidia Docker Runtimeをデフォルトとして使用する必要があります。詳細は[こちら](https://stackoverflow.com/questions/59691207/docker-build-with-nvidia-runtime)をご覧ください。 +> [プロジェクトページ](https://www.colossalai.org)から直接Colossal-AIをインストールすることをお勧めします。 + + +```bash +cd ColossalAI +docker build -t colossalai ./docker +``` + +以下のコマンドでインタラクティブモードでDockerコンテナを起動します。 + +```bash +docker run -ti --gpus all --rm --ipc=host colossalai bash +``` + +(トップに戻る)
+ +## コミュニティ + +[フォーラム](https://github.com/hpcaitech/ColossalAI/discussions)、 +[Slack](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w)、 +[WeChat(微信)](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png "qrcode")でColossal-AIコミュニティに参加し、エンジニアリングチームにご意見、フィードバック、質問を共有してください。 + +## コントリビューション +[BLOOM](https://bigscience.huggingface.co/)や[Stable Diffusion](https://en.wikipedia.org/wiki/Stable_Diffusion)の成功事例を参考に、計算リソース、データセット、モデルをお持ちのすべての開発者やパートナーの皆さまを歓迎します。Colossal-AIコミュニティに参加し、大規模AIモデルの時代に向けて一緒に取り組みましょう! + +以下の方法でお問い合わせまたはご参加いただけます: +1. [スターを付ける ⭐](https://github.com/hpcaitech/ColossalAI/stargazers) で応援とサポートを表明。ありがとうございます! +2. [issue](https://github.com/hpcaitech/ColossalAI/issues/new/choose)の投稿、または[コントリビューションガイドライン](https://github.com/hpcaitech/ColossalAI/blob/main/CONTRIBUTING.md)に従ってGitHubでPRを提出 +3. 公式提案をメール contact@hpcaitech.com に送信 + +素晴らしいコントリビューターの皆さまに感謝します! + + +(トップに戻る)
+ + +## CI/CD + +[GitHub Actions](https://github.com/features/actions)を活用して、開発、リリース、デプロイメントのワークフローを自動化しています。自動化されたワークフローの運用方法については、この[ドキュメント](.github/workflows/README.md)をご確認ください。 + + +## 引用 + +このプロジェクトはいくつかの関連プロジェクト(私たちのチームおよび他の組織によるもの)にインスパイアされています。[参考文献リスト](./REFERENCE.md)に記載されているこれらの素晴らしいプロジェクトに感謝します。 + +このプロジェクトを引用するには、以下のBibTeX引用をご使用ください。 + +``` +@inproceedings{10.1145/3605573.3605613, +author = {Li, Shenggui and Liu, Hongxin and Bian, Zhengda and Fang, Jiarui and Huang, Haichen and Liu, Yuliang and Wang, Boxiang and You, Yang}, +title = {Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training}, +year = {2023}, +isbn = {9798400708435}, +publisher = {Association for Computing Machinery}, +address = {New York, NY, USA}, +url = {https://doi.org/10.1145/3605573.3605613}, +doi = {10.1145/3605573.3605613}, +abstract = {The success of Transformer models has pushed the deep learning model scale to billions of parameters, but the memory limitation of a single GPU has led to an urgent need for training on multi-GPU clusters. However, the best practice for choosing the optimal parallel strategy is still lacking, as it requires domain expertise in both deep learning and parallel computing. The Colossal-AI system addressed the above challenge by introducing a unified interface to scale your sequential code of model training to distributed environments. It supports parallel training methods such as data, pipeline, tensor, and sequence parallelism and is integrated with heterogeneous training and zero redundancy optimizer. Compared to the baseline system, Colossal-AI can achieve up to 2.76 times training speedup on large-scale models.}, +booktitle = {Proceedings of the 52nd International Conference on Parallel Processing}, +pages = {766–775}, +numpages = {10}, +keywords = {datasets, gaze detection, text tagging, neural networks}, +location = {Salt Lake City, UT, USA}, +series = {ICPP '23} +} +``` + +Colossal-AIはトップカンファレンス [NeurIPS](https://nips.cc/)、[SC](https://sc22.supercomputing.org/)、[AAAI](https://aaai.org/Conferences/AAAI-23/)、 +[PPoPP](https://ppopp23.sigplan.org/)、[CVPR](https://cvpr2023.thecvf.com/)、[ISC](https://www.isc-hpc.com/)、[NVIDIA GTC](https://www.nvidia.com/en-us/on-demand/session/gtcspring23-S51482/)等の公式チュートリアルとして採択されています。 diff --git a/docs/README-zh-Hans.md b/docs/README-zh-Hans.md index 0e175afb0e63..ce04a5738cc7 100644 --- a/docs/README-zh-Hans.md +++ b/docs/README-zh-Hans.md @@ -20,7 +20,7 @@ [](https://github.com/hpcaitech/public_assets/tree/main/colossalai/contact/slack) [](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png) - | [English](README.md) | [中文](README-zh-Hans.md) | + | [English](README.md) | [中文](README-zh-Hans.md) | [日本語](README-ja.md) |