From a54db6153762e6b1fece53b9f6941fb348a6b45d Mon Sep 17 00:00:00 2001
From: HarryHe628 <2724851699@qq.com>
Date: Sun, 10 May 2026 20:22:04 +0800
Subject: [PATCH] Add Chinese translations for all documentation files
Add _zh.md versions of README, cookbook, doc-search tutorials, and
tree-search tutorial. Code blocks remain in original English.
---
README_zh.md | 276 ++++++++++++++++++
cookbook/README_zh.md | 14 +
examples/tutorials/doc-search/README_zh.md | 14 +
.../tutorials/doc-search/description_zh.md | 64 ++++
examples/tutorials/doc-search/metadata_zh.md | 35 +++
examples/tutorials/doc-search/semantics_zh.md | 35 +++
examples/tutorials/tree-search/README_zh.md | 67 +++++
7 files changed, 505 insertions(+)
create mode 100644 README_zh.md
create mode 100644 cookbook/README_zh.md
create mode 100644 examples/tutorials/doc-search/README_zh.md
create mode 100644 examples/tutorials/doc-search/description_zh.md
create mode 100644 examples/tutorials/doc-search/metadata_zh.md
create mode 100644 examples/tutorials/doc-search/semantics_zh.md
create mode 100644 examples/tutorials/tree-search/README_zh.md
diff --git a/README_zh.md b/README_zh.md
new file mode 100644
index 000000000..276ac7ad0
--- /dev/null
+++ b/README_zh.md
@@ -0,0 +1,276 @@
+
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+# PageIndex:无向量、推理驱动的 RAG
+
+
基于推理的 RAG ◦ 无需向量数据库与文档切片 ◦ 上下文感知 ◦ 类人检索
+
+
+
+
+📢 最新动态
+
+- 🔥 [**Agentic 无向量 RAG**](https://github.com/VectifyAI/PageIndex/blob/main/examples/agentic_vectorless_rag_demo.py) — 基于 OpenAI Agents SDK 的简易 *agentic 无向量 RAG* [示例](#agentic-vectorless-rag-示例),使用自托管 PageIndex。
+- [**PageIndex 扩展到百万级文档**](https://pageindex.ai/blog/pageindex-filesystem) — *PageIndex 文件系统* 是文件级树状索引层,让 PageIndex 能够在整个语料库(而非单篇文档)上进行推理,实现大规模文档搜索。
+- [PageIndex Chat](https://chat.pageindex.ai) — 面向专业长文档的类人文档分析 agent [平台](https://chat.pageindex.ai)。同时支持 [MCP](https://pageindex.ai/developer) 与 [API](https://pageindex.ai/developer) 接入。
+- [PageIndex 框架](https://pageindex.ai/blog/pageindex-intro) — 深入解读 PageIndex:一种 *agentic 上下文树索引*,使 LLM 能够对长文档进行*基于推理的上下文感知检索*。
+
+
+
+---
+
+# 📑 PageIndex 简介
+
+你是否对向量数据库在专业长文档上的检索精度感到困扰?传统的基于向量的 RAG 依赖语义*相似度*而非真正的*相关性*。但**相似度 ≠ 相关性**——检索真正需要的是**相关性**,而这需要**推理**。当处理需要专业领域知识和多步推理的专业文档时,相似度搜索往往力不从心。
+
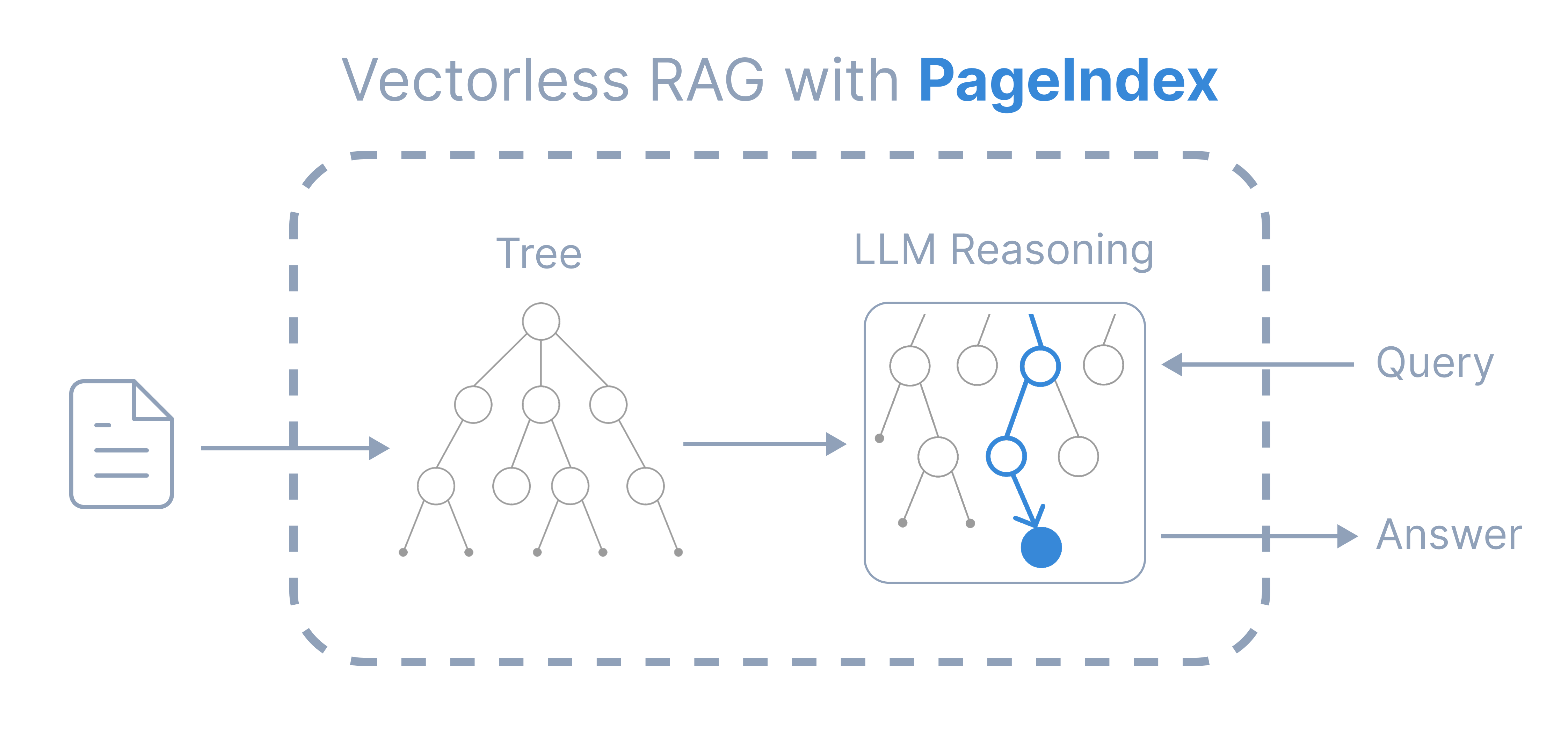
+受 AlphaGo 的启发,我们提出了 **[PageIndex](https://vectify.ai/pageindex)**——一种**无向量**、**推理驱动**的 RAG 系统。它从长文档中构建**层次树状索引**,并利用 LLM **在该索引上进行推理**,实现 **agentic、上下文感知的检索**。它模拟了*人类专家*通过*树搜索*在复杂文档中导航和提取知识的方式,使 LLM 能够*思考*和*推理*出最相关的文档章节。PageIndex 的检索分为两步:
+
+1. 生成文档的"目录式"**树结构索引**
+2. 通过**树搜索**进行基于推理的检索
+
+
+
+### 🎯 核心特性
+
+与传统基于向量的 RAG 相比,**PageIndex** 具有以下特点:
+- **无需向量数据库**:利用文档结构和 LLM 推理进行检索,而非向量相似度搜索。
+- **无需文档切片**:文档按自然章节组织,而非人为切分的片段。
+- **更好的可解释性与可追溯性**:检索基于推理,可追溯、可解释,附带页面和章节引用。告别不透明的近似向量搜索("凭感觉检索")。
+- **上下文感知检索**:检索依赖完整上下文(如对话历史和领域知识),并能轻松融入新的上下文信息。
+- **类人检索**:模拟人类专家在复杂文档中导航和提取知识的方式。
+
+PageIndex 驱动的推理型 RAG 系统在 FinanceBench 上取得了**业界领先的 [98.7% 准确率](https://github.com/VectifyAI/Mafin2.5-FinanceBench)**,展现了其在专业文档分析中远超向量 RAG 方案的卓越性能。详见我们的[博客文章](https://vectify.ai/blog/Mafin2.5)。
+
+### 📍 探索 PageIndex
+
+了解更多,请参阅 [PageIndex 框架](https://pageindex.ai/blog/pageindex-intro)的详细介绍。在本 GitHub 仓库中可获取开源代码,同时可查看 [Cookbooks](https://docs.pageindex.ai/cookbook)、[教程](https://docs.pageindex.ai/tutorials) 和[博客](https://pageindex.ai/blog)获取更多使用指南和示例。
+
+PageIndex 服务以 ChatGPT 风格的[对话平台](https://chat.pageindex.ai)提供,也可通过 [MCP](https://pageindex.ai/developer) 或 [API](https://pageindex.ai/developer) 集成。
+
+### 🛠️ 部署方式
+- **自托管** — 使用本开源仓库在本地运行(使用标准 PDF 解析)。
+- **云服务** — 生产级管线,拥有增强的 OCR、树构建和检索能力,以获得最佳效果。可立即在[对话平台](https://chat.pageindex.ai/)上体验,或通过 [MCP](https://pageindex.ai/developer) 与 [API](https://pageindex.ai/developer) 集成。
+- **企业版** — 私有化或本地部署。[联系我们](https://ii2abc2jejf.typeform.com/to/tK3AXl8T) 或[预约演示](https://calendly.com/pageindex/meet)了解更多。
+
+### 🧪 快速上手
+
+- 🔥 [**Agentic 无向量 RAG**](examples/agentic_vectorless_rag_demo.py)(**最新**)— 基于 OpenAI Agents SDK 的简易完整 **agentic 无向量 RAG** [示例](#agentic-vectorless-rag-示例),使用*自托管* PageIndex。
+- 试用 [Vectorless RAG](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/pageindex_RAG_simple.ipynb) Notebook — 使用 PageIndex 进行推理型 RAG 的*最小化*、实战示例。
+- 查看 [Vision-based Vectorless RAG](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/vision_RAG_pageindex.ipynb) — 无需 OCR;直接基于页面图像的最小化视觉推理型 RAG 管线。
+
+
+
+---
+
+# 🌲 PageIndex 树结构
+
+PageIndex 可以将冗长的 PDF 文档转化为语义**树结构**,类似于*目录*,但针对大语言模型 (LLM) 的使用进行了优化。它适用于:财务报告、监管文件、学术教材、法律或技术手册,以及任何超出 LLM 上下文限制的文档。
+
+以下是 PageIndex 树结构示例。也可查看更多的示例[文档](https://github.com/VectifyAI/PageIndex/tree/main/examples/documents)和生成的[树结构](https://github.com/VectifyAI/PageIndex/tree/main/examples/documents/results)。
+
+```jsonc
+...
+{
+ "title": "Financial Stability",
+ "node_id": "0006",
+ "start_index": 21,
+ "end_index": 22,
+ "summary": "The Federal Reserve ...",
+ "nodes": [
+ {
+ "title": "Monitoring Financial Vulnerabilities",
+ "node_id": "0007",
+ "start_index": 22,
+ "end_index": 28,
+ "summary": "The Federal Reserve's monitoring ..."
+ },
+ {
+ "title": "Domestic and International Cooperation and Coordination",
+ "node_id": "0008",
+ "start_index": 28,
+ "end_index": 31,
+ "summary": "In 2023, the Federal Reserve collaborated ..."
+ }
+ ]
+}
+...
+```
+
+你可以使用此开源仓库生成 PageIndex 树结构,或使用我们的 [API](https://pageindex.ai/developer) 获取由增强 OCR 和树构建管线驱动的更高质量结果。
+
+---
+
+# ⚙️ 使用指南
+
+> **注意:** 本包使用标准 PDF 解析。对于复杂 PDF 的使用场景,我们的[云服务](https://pageindex.ai/developer)(通过 MCP 和 API)提供增强的 OCR、树构建和检索能力。
+
+按照以下步骤,从 PDF 文档生成 PageIndex 树结构。
+
+### 1. 安装依赖
+
+```bash
+pip3 install --upgrade -r requirements.txt
+```
+
+### 2. 设置 LLM API 密钥
+
+在项目根目录创建 `.env` 文件,填入你的 LLM API 密钥。通过 [LiteLLM](https://docs.litellm.ai/docs/providers) 支持多种 LLM:
+
+```bash
+OPENAI_API_KEY=your_openai_key_here
+```
+
+### 3. 为你的 PDF 生成 PageIndex 结构
+
+```bash
+python3 run_pageindex.py --pdf_path /path/to/your/document.pdf
+```
+
+
+可选参数
+
+你可以通过以下可选参数自定义处理流程:
+
+```
+--model LLM model to use (default: gpt-4o-2024-11-20)
+--toc-check-pages Pages to check for table of contents (default: 20)
+--max-pages-per-node Max pages per node (default: 10)
+--max-tokens-per-node Max tokens per node (default: 20000)
+--if-add-node-id Add node ID (yes/no, default: yes)
+--if-add-node-summary Add node summary (yes/no, default: yes)
+--if-add-doc-description Add doc description (yes/no, default: yes)
+```
+
+
+
+Markdown 支持
+
+PageIndex 同样支持 Markdown 文件。你可以使用 `--md_path` 参数为 Markdown 文件生成树结构。
+
+```bash
+python3 run_pageindex.py --md_path /path/to/your/document.md
+```
+
+> 注意:在此模式下,我们使用 "#" 来确定节点标题及其层级。例如,"##" 为第 2 级,"###" 为第 3 级,以此类推。请确保你的 Markdown 文件格式正确。如果你的 Markdown 文件是从 PDF 或 HTML 转换而来的,我们不建议使用此模式,因为大多数现有转换工具无法保留原始层级结构。此时建议使用我们的 [PageIndex OCR](https://pageindex.ai/blog/ocr)(专为保留层级结构设计)将 PDF 转换为 Markdown 文件后再使用此模式。
+
+
+## Agentic 无向量 RAG 示例
+
+关于使用 PageIndex 与 OpenAI Agents SDK 构建端到端 _**agentic 无向量 RAG**_ 的简易示例,请参见 [`examples/agentic_vectorless_rag_demo.py`](examples/agentic_vectorless_rag_demo.py)。
+
+```bash
+# Install optional dependency
+pip3 install openai-agents
+
+# Run the demo
+python3 examples/agentic_vectorless_rag_demo.py
+```
+
+---
+
+# 📈 案例研究:PageIndex 领跑金融 QA 基准
+
+[Mafin 2.5](https://vectify.ai/mafin) 是由 **PageIndex** 驱动的金融文档分析推理型 RAG 系统。它在 [FinanceBench](https://arxiv.org/abs/2311.11944) 基准上取得了业界领先的 [**98.7% 准确率**](https://vectify.ai/blog/Mafin2.5),显著超越传统的向量 RAG 系统。
+
+PageIndex 的层次索引和推理驱动检索,能够精准导航并提取复杂金融报告(如 SEC 文件和财报披露)中的相关内容。
+
+查看完整的[基准测试结果](https://github.com/VectifyAI/Mafin2.5-FinanceBench)和我们的[博客文章](https://vectify.ai/blog/Mafin2.5),了解详细的对比和性能指标。
+
+
+
+---
+
+# 🧭 资源
+
+* 📝 [博客](https://pageindex.ai/blog):技术文章、研究洞察和产品更新。
+* 🔧 [开发者](https://pageindex.ai/developer):MCP 配置、API 文档和集成指南。
+* 🧪 [Cookbooks](https://docs.pageindex.ai/cookbook):可运行的实战示例和高级用例。
+* 📖 [教程](https://docs.pageindex.ai/tutorials):实用指南和策略,包括*文档搜索*和*树搜索*。
+
+---
+
+# ⭐ 支持我们
+
+如果你喜欢我们的项目,请给我们一颗星 🌟。感谢!
+
+
+  +
+
+
+请引用本工作:
+```
+Mingtian Zhang, Yu Tang and PageIndex Team,
+"PageIndex: Next-Generation Vectorless, Reasoning-based RAG",
+PageIndex Blog, Sep 2025.
+```
+
+
+或使用 BibTeX 引用。
+
+```bibtex
+@article{zhang2025pageindex,
+ author = {Mingtian Zhang and Yu Tang and PageIndex Team},
+ title = {PageIndex: Next-Generation Vectorless, Reasoning-based RAG},
+ journal = {PageIndex Blog},
+ year = {2025},
+ month = {September},
+ note = {https://pageindex.ai/blog/pageindex-intro},
+}
+```
+
+
+
+### 与我们联系
+
+
+
+[](https://x.com/PageIndexAI)
+[](https://www.linkedin.com/company/vectify-ai/)
+[](https://discord.com/invite/VuXuf29EUj)
+[](https://ii2abc2jejf.typeform.com/to/tK3AXl8T)
+
+
+
+---
+
+© 2026 [Vectify AI](https://vectify.ai)
diff --git a/cookbook/README_zh.md b/cookbook/README_zh.md
new file mode 100644
index 000000000..0d0e796d3
--- /dev/null
+++ b/cookbook/README_zh.md
@@ -0,0 +1,14 @@
+### 🧪 Cookbooks:
+
+* [**Vectorless RAG Notebook**](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/pageindex_RAG_simple.ipynb):使用 **PageIndex** 进行推理型 RAG 的*最小化*实战示例——无需向量、无需切片、类人检索。
+* [Vision-based Vectorless RAG Notebook](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/vision_RAG_pageindex.ipynb):无需 OCR;直接基于页面图像进行检索与推理的原生推理型 RAG 管线。
+
+
diff --git a/examples/tutorials/doc-search/README_zh.md b/examples/tutorials/doc-search/README_zh.md
new file mode 100644
index 000000000..943bf72f4
--- /dev/null
+++ b/examples/tutorials/doc-search/README_zh.md
@@ -0,0 +1,14 @@
+
+## 文档搜索 示例
+
+PageIndex 目前默认支持在单篇文档内进行基于推理的 RAG 检索。
+对于需要跨文档搜索的用户,我们针对不同场景提供了以下三种最佳实践工作流。
+
+* [**按元数据搜索:**](metadata_zh.md) 适用于可以通过元数据进行区分的文档。
+* [**按语义搜索:**](semantics_zh.md) 适用于语义内容不同或涵盖多种主题的文档。
+* [**按描述搜索:**](description_zh.md) 针对少量文档的轻量级策略。
+
+## 💬 支持
+
+* 🤝 [加入我们的 Discord](https://discord.gg/VuXuf29EUj)
+* 📨 [联系我们](https://ii2abc2jejf.typeform.com/to/meB40zV0)
diff --git a/examples/tutorials/doc-search/description_zh.md b/examples/tutorials/doc-search/description_zh.md
new file mode 100644
index 000000000..5de253375
--- /dev/null
+++ b/examples/tutorials/doc-search/description_zh.md
@@ -0,0 +1,64 @@
+
+## 按描述搜索文档
+
+对于没有元数据的文档,可以使用 LLM 生成的描述来辅助文档筛选。这是一种轻量级方法,最适用于少量文档的场景。
+
+### 示例流程
+
+#### 生成 PageIndex 树结构
+将所有文档上传至 PageIndex,获取其 `doc_id` 和树结构。
+
+#### 生成文档描述
+
+基于每篇文档的 PageIndex 树结构和节点摘要,为每篇文档生成一句话描述。
+
+```python
+prompt = f"""
+You are given a table of contents structure of a document.
+Your task is to generate a one-sentence description for the document that makes it easy to distinguish from other documents.
+
+Document tree structure: {PageIndex_Tree}
+
+Directly return the description, do not include any other text.
+"""
+```
+
+#### 使用 LLM 搜索
+
+使用 LLM 将用户查询与生成的文档描述进行对比,从而选取相关文档。
+
+以下是根据文档描述进行文档选取的示例提示词:
+
+```python
+prompt = f"""
+You are given a list of documents with their IDs, file names, and descriptions. Your task is to select documents that may contain information relevant to answering the user query.
+
+Query: {query}
+
+Documents: [
+ {
+ "doc_id": "xxx",
+ "doc_name": "xxx",
+ "doc_description": "xxx"
+ }
+]
+
+Response Format:
+{{
+ "thinking": "",
+ "answer": , e.g. ['doc_id1', 'doc_id2']. Return [] if no documents are relevant.
+}}
+
+Return only the JSON structure, with no additional output.
+"""
+```
+
+#### 使用 PageIndex 检索
+
+使用已筛选出的文档的 PageIndex `doc_id`,通过 PageIndex 检索 API 进行进一步的检索。
+
+## 💬 帮助与社区
+如果你需要关于在你的场景中如何实施文档搜索的建议,请联系我们。
+
+- 🤝 [加入我们的 Discord](https://discord.gg/VuXuf29EUj)
+- 📨 [给我们留言](https://ii2abc2jejf.typeform.com/to/meB40zV0)
diff --git a/examples/tutorials/doc-search/metadata_zh.md b/examples/tutorials/doc-search/metadata_zh.md
new file mode 100644
index 000000000..d11ef3236
--- /dev/null
+++ b/examples/tutorials/doc-search/metadata_zh.md
@@ -0,0 +1,35 @@
+
+## 按元数据搜索文档
+支持元数据的 PageIndex 功能目前处于封闭测试阶段。请填写此表单以申请该功能的提前体验权限。
+
+对于可以轻松通过元数据进行区分的文档,我们推荐使用元数据来搜索文档。
+此方法特别适合以下文档类型:
+- 按公司和时间段分类的财务报告
+- 按案件类型分类的法律文件
+- 按患者或病情分类的医疗记录
+- 以及更多其他类型
+
+在此类场景中,你可以利用文档的元数据进行搜索。一种流行的做法是使用 "Query to SQL" 来进行文档检索。
+
+### 示例流程
+
+#### 生成 PageIndex 树结构
+将所有文档上传至 PageIndex,获取其 `doc_id`。
+
+#### 建立 SQL 数据表
+
+将文档连同其元数据和 PageIndex `doc_id` 一起存入数据库表中。
+
+#### Query to SQL
+
+使用 LLM 将用户的检索请求转换为 SQL 查询,以获取相关文档。
+
+#### 使用 PageIndex 检索
+
+使用已筛选出的文档的 PageIndex `doc_id`,通过 PageIndex 检索 API 进行进一步的检索。
+
+## 💬 帮助与社区
+如果你需要关于在你的场景中如何实施文档搜索的建议,请联系我们。
+
+- 🤝 [加入我们的 Discord](https://discord.gg/VuXuf29EUj)
+- 📨 [给我们留言](https://ii2abc2jejf.typeform.com/to/meB40zV0)
diff --git a/examples/tutorials/doc-search/semantics_zh.md b/examples/tutorials/doc-search/semantics_zh.md
new file mode 100644
index 000000000..f05777562
--- /dev/null
+++ b/examples/tutorials/doc-search/semantics_zh.md
@@ -0,0 +1,35 @@
+## 按语义搜索文档
+
+对于涵盖多种主题的文档,也可以使用基于向量的语义搜索来检索文档。其流程与经典的向量搜索方法略有不同。
+
+### 示例流程
+
+#### 切片与向量嵌入
+将文档分割为若干片段,选择嵌入模型将片段转化为向量,并将每个向量与其对应的 `doc_id` 一起存入向量数据库。
+
+#### 向量搜索
+
+对于每个查询,执行基于向量的搜索,获取 Top-K 个片段及其对应的文档。
+
+#### 计算文档得分
+
+为每篇文档计算相关性得分。设 N 为每篇文档关联的内容片段数量,**ChunkScore**(n) 为第 n 个片段的相关性得分。文档得分计算公式如下:
+
+$$
+\text{DocScore}=\frac{1}{\sqrt{N+1}}\sum_{n=1}^N \text{ChunkScore}(n)
+$$
+
+- 分子求和汇总了所有相关片段的相关性。
+- 分母中 +1 的作用是确保在节点包含零个片段时公式依然有效。
+- 使用平方根作为分母,使得得分能够随相关片段数量的增加而提高,但增幅递减。这能奖励拥有更多相关片段的文档,同时防止大型节点仅凭数量优势占据主导地位。
+- 此评分方式更偏向于拥有少量高相关片段的文档,而非大量弱相关片段的文档。
+
+#### 使用 PageIndex 检索
+
+选取 DocScore 最高的若干文档,然后使用其 `doc_id` 通过 PageIndex 检索 API 进行进一步的检索。
+
+## 💬 帮助与社区
+如果你需要关于在你的场景中如何实施文档搜索的建议,请联系我们。
+
+- 🤝 [加入我们的 Discord](https://discord.gg/VuXuf29EUj)
+- 📨 [给我们留言](https://ii2abc2jejf.typeform.com/to/meB40zV0)
diff --git a/examples/tutorials/tree-search/README_zh.md b/examples/tutorials/tree-search/README_zh.md
new file mode 100644
index 000000000..bf4966e94
--- /dev/null
+++ b/examples/tutorials/tree-search/README_zh.md
@@ -0,0 +1,67 @@
+## 树搜索 示例
+本教程提供了使用 PageIndex 树结构进行检索的基础示例。
+
+### 基础 LLM 树搜索示例
+一种简单的策略是使用 LLM agent 进行树搜索。以下是一个基础的树搜索提示词。
+
+```python
+prompt = f"""
+You are given a query and the tree structure of a document.
+You need to find all nodes that are likely to contain the answer.
+
+Query: {query}
+
+Document tree structure: {PageIndex_Tree}
+
+Reply in the following JSON format:
+{{
+ "thinking": ,
+ "node_list": [node_id1, node_id2, ...]
+}}
+"""
+```
+
+在我们的控制台和检索 API 中,我们使用了 LLM 树搜索与基于价值函数的蒙特卡洛树搜索([MCTS](https://en.wikipedia.org/wiki/Monte_Carlo_tree_search))相结合的方式。更多细节即将发布。
+
+
+### 融合用户偏好或专家知识
+与基于向量的 RAG 不同——后者需要微调嵌入模型才能融入专家知识或用户偏好——在 PageIndex 中,你只需将用户偏好或专家知识直接添加到 LLM 树搜索提示词中即可。以下是一个示例流程。
+
+#### 1. 偏好检索
+
+当收到查询时,系统会从数据库或一组领域规则中选取最相关的用户偏好或专家知识片段。这可以通过关键词匹配、语义相似度或基于 LLM 的相关性搜索来实现。
+
+#### 2. 结合偏好的树搜索
+将偏好融入树搜索提示词中。
+
+**融合专家偏好的增强树搜索示例**
+
+```python
+prompt = f"""
+You are given a question and a tree structure of a document.
+You need to find all nodes that are likely to contain the answer.
+
+Query: {query}
+
+Document tree structure: {PageIndex_Tree}
+
+Expert Knowledge of relevant sections: {Preference}
+
+Reply in the following JSON format:
+{{
+ "thinking": ,
+ "node_list": [node_id1, node_id2, ...]
+}}
+"""
+```
+
+**专家偏好示例**
+> If the query mentions EBITDA adjustments, prioritize Item 7 (MD&A) and footnotes in Item 8 (Financial Statements) in 10-K reports.
+
+通过融合用户或专家偏好,节点搜索变得更加精准有效,同时利用了文档结构和领域专长两方面的优势。
+
+## 💬 帮助与社区
+如果你需要关于在你的场景中如何实施文档搜索的建议,请联系我们。
+
+- 🤝 [加入我们的 Discord](https://discord.gg/VuXuf29EUj)
+- 📨 [给我们留言](https://ii2abc2jejf.typeform.com/to/tK3AXl8T)
 +
+
+
+